Historikerinnen und Historiker arbeiten mit vielfältigsten Texten, in denen sie die Geschichte des Menschen und der Welt lesen und ihre Einsichten der Forschungscommunity und der Öffentlichkeit vorzugsweise schreibend kommunizieren. Zu diesen Texten gehört das breite Portfolio an Forschungsliteratur genauso wie die Vielfalt historischer Quellen in Gestalt von Texten – seien es handschriftliche oder gedruckte textuelle Überlieferungen in Urkunden, historiografischen und literarischen Texten oder in nicht-textuellen kulturellen Artefakten. Sowohl Forschungsliteratur als auch Quellen liegen zunehmend in Volltextdatenbanken vor, die das digitale geschichtswissenschaftliche Arbeiten in Studium, Forschung und Lehre grundlegend prägen.[1]
Volltextdatenbanken sind daher einerseits Archive handschriftlicher und gedruckter Textquellen, andererseits Repositorien und Räume geschichtswissenschaftlicher Diskurse in selbstständigen[2] und unselbstständigen[3] Forschungsbeiträgen, die zunehmend vernetzt und interaktiv ausgestaltet werden. Dieser Guide legt im Folgenden den Fokus auf Volltextdatenbanken historischer Quellen.
Historische Volltextdatenbanken können entweder auf genuin digitalen oder retrodigitalisierten einzelnen Texten oder Sammlungen von Büchern und Objekten in Bibliotheken, Archiven und Museen basieren. Die Zusammenführung von Einzeltexten oder Textcorpora orientiert sich häufig an chronologischen, regionalen oder thematischen Kriterien, die auch für die Unterscheidung der Guides dieses Handbuchs bestimmend sind. Als Ergebnis dieser Aufbereitung von Texten präsentiert sich die historische Volltextdatenbank als eine in der Regel Einzeltexte oder Einzelbestände übergreifende digitale Textsammlung. Folgerichtig ist der Guide „Historische Volltextdatenbanken“ in den Teil „Sammlungen“ eingebettet.
Eng verbunden mit Volltextdatenbanken sind die Digital Humanities: Diese entwickeln komplexe Werkzeuge und Methoden, mit denen Volltexte generiert, analysiert, visualisiert und bearbeitet werden können, um zu historischen Erkenntnissen zu gelangen, die im Zeitalter analoger Texte und Textüberlieferung so nicht möglich gewesen wären. 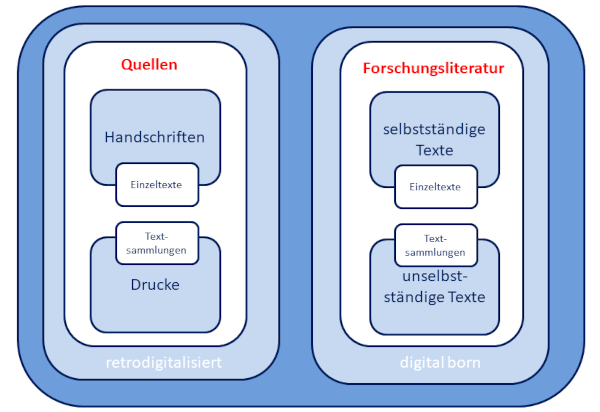
Abbildung 1. Typen von Volltexten
Zugleich erfordert der Umgang mit digitalen Quellen eine spezifisch digitale Quellenkritik. Welche Rolle historische Volltextdatenbanken in diesen komplexen Prozessen spielen, möchte dieser Guide zeigen.
Die Geschichte der Geisteswissenschaften ist nicht nur eng mit der Geschichte der Institutionen des kulturellen Gedächtnisses, den Archiven, Bibliotheken und Museen, sondern auch mit der Geschichte der schriftbasierten Kulturtechniken Lesen und Schreiben verbunden.[4] Nach Justus Lipsius (1547–1606)[5] wurde die Bibliothek gemeinsam mit der Schrift erfunden.[6] Daher soll das Thema Historische Volltextdatenbanken in den engen Kontext der Schrift-, Buch- und Bibliotheksgeschichte gestellt werden. Die kulturgeschichtliche Leistung der Gedächtnisinstitutionen ist die planvolle Sammlung und Aufbewahrung handschriftlicher und gedruckter Texte oder Artefakte menschlicher Kultur. Bibliotheken stellen zugleich Strukturen bereit, in denen Menschen, die mit Texten arbeiten, sich bewegen. Die Geschichte von Texten und Büchern ist zugleich die Geschichte von Leserinnen und Lesern, aus denen im Raum realer und virtueller Bibliotheken Autorinnen und Autoren werden.
Eine erste Herausforderung für Archive, Bibliotheken und Museen war das Ende der Manuskriptkultur im 15. Jahrhundert – bis dahin wurden Texte einzeln handschriftlich in den Skriptorien der Klöster kopiert und in den daran angeschlossenen Bibliotheken aufbewahrt.
Mit dem Beginn des nach dem Mainzer Buchdrucker Johannes Gutenberg als Gutenberg-Galaxis[7] bezeichneten Buchzeitalters begann das exponentielle Wachstum gedruckter Texte und damit die wachsende Komplexität der Gedächtnisinstitutionen: Bibliotheken wuchsen nicht nur physisch, auch das Sammeln von Büchern und das Organisieren des in diesen dokumentierten Wissens stellte sie vor immer neue Herausforderungen. Da keine einzelne Institution das gesamte, in Büchern fixierte Weltwissen sammeln konnte, sondern dieses über zahllose Archive, Bibliotheken und Museen hinweg verstreut war, lag die Herausforderung für Forschende darin, die für sie relevanten Bücher überhaupt erst zu finden. Praktisch bedeutete dies, sich auf Reisen zu begeben und die Texte zu finden, zu lesen und zu exzerpieren. Forschende wurden vielfach selbst zu Autorinnen und Autoren, deren neue Erkenntnisse in eigenen gedruckten Texten wiederum neue Lektüren und Texte anstießen.
Zu den vor-digitalen, analogen Grundlagen historischer Volltextdatenbanken gehören nicht nur handschriftliche und gedruckte Schriftquellen, sondern auch ihre Editionen in zum Teil umfassenden Corpora. Sie sind Ergebnisse forschenden Reisens zu Bibliotheken. Viele dieser insbesondere seit dem 19. Jahrhundert entstandenen Monumente der Wissenschaftsgeschichte wie die Monumenta Germaniae Historica (MGH) oder die Regesta Imperii (RI) sind heute in Volltextdatenbanken transformiert und ermöglichen Methoden eines distant reading.
Vielfältige Innovationen bei der Reproduktion von Texten im 20. Jahrhundert waren ein erster Schritt zur Überwindung der Gutenberg-Galaxis. Sie veränderten nicht nur die Sammeltätigkeit von Bibliotheken, sondern auch das Arbeiten mit ihnen. Die analogen Vorläufer historischer Volltextdatenbanken entstanden aus der Reproduktion handschriftlicher und gedruckter Einzeltexte oder Textsammlungen in umfangreichen, kumulierten Corpora in Mikroform-Archiven (Mikrofilm, Mikrofiche). Bereits hier wurde angestrebt, chronologisch, regional oder thematisch verwandte Texte zusammenzuführen. An ihrer Erstellung waren Bibliotheken in Kooperation mit Verlagen nicht nur aktiv beteiligt, sie erweiterten durch die Erwerbung derartiger Mikroform-Kopien der in anderen Bibliotheken verfügbaren Bestände ihre eigenen Sammlungen signifikant. Dennoch blieb dieser Schatz an Texten und an Wissen häufig verborgen – lag (und liegt) doch eine Barriere für die Benutzung in der Notwendigkeit, wenig komfortable Lesegeräte verwenden zu müssen. Volltextrecherchen, wie sie Volltextdatenbanken ermöglichen, waren im Falle von Mikroform-Archiven nicht möglich.
Überwand die „Gutenberg-Galaxis“ im 15. Jahrhundert die Manuskriptkultur der Vormoderne, so wird seit Beginn des 21. Jahrhunderts die ein halbes Jahrtausend währende Epoche der „schwarzen Kunst“ durch das Zeitalter der Digitalisierung und der elektronischen Medien abgelöst. Historische Volltextdatenbanken entstanden – und entstehen – im konkreten Kontext der Entwicklung von der Digitalisierung zur digitalen Transformation während der noch andauernden Revolution unserer Schriftkultur. Meilensteine der Digitalisierung in deutschen wissenschaftlichen Bibliotheken war die Gründung der durch die Deutsche Forschungsgemeinschaft (DFG) geförderten Digitalisierungszentren an der Bayerischen Staatsbibliothek München und an der Niedersächsischen Staats- und Universitätsbibliothek Göttingen im Jahr 1997. Beide widmeten sich von Beginn an der Retrodigitalisierung ihrer historischen Bestände – den Quellen geschichtswissenschaftlichen Arbeitens. Diese sind heute Grundlage historischer Volltextdatenbanken für Quellen.
Da die Qualität eines Digitalisats entscheidend für dessen wissenschaftliche Weiterverarbeitung ist, wurden von Anfang an verbindliche Standards nicht nur für technische Parameter und Präsentation der Digitalisate, sondern auch für ihre formale und inhaltliche Erschließung in Praxisregeln für die Digitalisierung[9] festgelegt. Das Göttinger Digitalisierungszentrum (GDZ) widmete sich unter anderem im Projekt Gutenberg Digital der Digitalisierung des Göttinger Exemplars der berühmten Mainzer Bibel[12], mit der die Gutenberg-Galaxis ihren Ausgang nahm: Sie war eines der ersten Bücher, die in das digitale Zeitalter transformiert wurden. Das Münchener Digitalisierungszentrum (MDZ) legte einen Fokus unter anderem auf die Digitalisierung seiner weltweit einmaligen Inkunabelsammlung. Beide Institutionen trugen in vielfältigen Kooperationen dazu bei, dass die Digitalisierung historischer Bestände schrittweise in den Routinebetrieb auch kleinerer Bibliotheken mit historischen Beständen überführt werden konnte.
Seit Beginn der systematischen Digitalisierung historischer Bibliotheksbestände mit dem Ziel der Unterstützung von Studium, Lehre und Forschung der Zukunft wurden schrittweise analoge Einzelobjekte oder ganze Sammlungen in digitale Formate transformiert. Die so entstandenen digitalen Forschungsressourcen ergänzen – wie bereits zuvor die Mikroform-Archive – die in der individuellen Bibliothek physisch vorhandenen Texte und Sammlungen.
Digitalisate analoger Texte sind jedoch weit mehr als bloße Reproduktionen: Sie können im Volltext durchsucht, automatisch transkribiert, übersetzt, vorgelesen und digital weiterbearbeitet werden. Insofern prägt die Form der Vorlagen die Praktiken der Leserinnen und Leser sowie die Arbeitsweisen und -methoden der Historikerinnen und Historiker – und umgekehrt.
Die Frage, „welchen Stellenwert das Analoge im Digitalen hat, verändert doch die digitale Transformation auch ihren analogen Ausgangspunkt“[14], ist zu diskutieren. Den Weg von der Digitalisierung zur digitalen Transformation beschreiten die einzelnen Wissenschaftsdisziplinen in unterschiedlichen Geschwindigkeiten und mit eigenen Schwerpunkten. Für die Geschichtswissenschaften ist die Entwicklung der Digital Humanities mit ihren spezifischen Konzepten und Methoden zentral – exakt hier spielen die historischen Volltextdatenbanken eine zentrale Rolle.
Das Bewusstsein, dass das kulturelle Erbe das „unschätzbare Gewebe“ sei, das Europa zusammenhält, ließ die Europäische Kommission erstmals das Jahr 2018 als „Europäisches Jahr des Kulturerbes“ erklären. Hierbei wurde insbesondere die Digitalisierung für die Kulturvermittlung hervorgehoben, durch die die Europeana als Schaufenster des europäischen Kulturerbes erst möglich wurde. Dieser entscheidende Schritt von der Digitalisierung des schriftlichen Kulturerbes hin zur digitalen Transformation bedeutet für die Geistes- und Kulturwissenschaften einen Paradigmenwechsel, durch den die traditionellen hermeneutischen Methoden durch digitale Methoden und Werkzeuge erweitert werden.[18]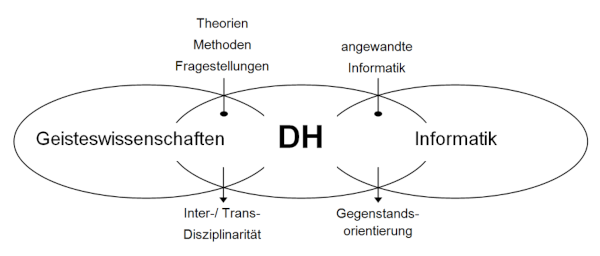
Abbildung 2. Digital Humanities als Brückendisziplin zwischen Geisteswissenschaften und Informatik (Grafik von Patrick Sahle, https://www.geschichte.uni-wuppertal.de/de/lehrgebiete/digital-humanities/)
In den Geistes- und Kulturwissenschaften hat diese Entwicklung zur Etablierung der Digital Humanities (DH) geführt, die sich mit der Anwendung und Reflexion computergestützter Verfahren und Instrumenten zur Bearbeitung digitaler Ressourcen befassen. Typische Arbeitsfelder sind qualitative Verfahren wie die Beschreibung, Transkription, Edition und Annotation digitalisierter Quellen beispielsweise durch digitale Manuskriptanalyse[19] einerseits oder quantitative Methoden wie die Analyse digitalisierter Texte durch Text Mining, Topic Modeling,[20] Textvisualisierung,[21] Stilometrie[22] oder Netzwerkanalyse andererseits.[23] Die dabei entstehenden technischen und inhaltlichen Metadaten sind als Forschungsdaten Rohstoff für künftige Analysen und Bearbeitungen. 
Abbildung 3. Arbeiten mit digitalen Texten in den Digital Humanities (Grafik der Inhalte von forTEXT, https://fortext.net/)
Perspektivisch lassen sich die Methoden und Tools der DH nicht nur in einen erweiterten Kanon der traditionellen historischen Grundwissenschaften[24] einbinden, sondern in eine digitale Quellenkritik und Hermeneutik, die Ergebnis der weiteren digitalen Transformation der Geschichtswissenschaften sein wird.
Die DH entwickeln sich gegenwärtig einerseits als eigenständige, die Geistes- und Kulturwissenschaften umfassende interdisziplinäre akademische Disziplin, andererseits finden ihre Konzepte Eingang in die einzelnen akademischen Fächer – wie beispielsweise in die Geschichtswissenschaften.[25] Hier werden sie den traditionellen Kanon der Grundwissenschaften substanziell ergänzen.[26]
Die Transformation des handschriftlichen und gedruckten schriftlichen Kulturerbes nach dem Ende der Gutenberg-Galaxis in eine maschinenlesbare Form wurde am Beginn des Computerzeitalters durch die Eingabe intellektuell erstellter Abschriften in elektronische Dokumente realisiert. Grundlage waren entweder die Originalquellen oder ihre Digitalisate. Während im ersten Fall ein Bearbeiter das Original aufsuchte, um dieses abzuschreiben, ermöglichte im zweiten Fall der ubiquitäre Zugriff auf Digitalisate eine Transkription auch durch beliebig viele Transkribierende in einem kollaborativen Dokument – beispielsweise in einem Transkribathon.[27] Mit dieser Übertragung eines Textes aus einer analogen oder digitalen Quelle in ein elektronisches Textverarbeitungsprogramm war der erste Schritt hin zu einer beliebig weiten Verbreitung digital codierter Texte gelungen – ein in der Geschichte der Schriftkultur revolutionärer Vorgang. In Volltextdatenbanken können diese transformierten Texte systematisch analysiert und weiterverarbeitet werden.
Dieses Verfahren individuell oder kollaborativ intellektuell erstellter elektronischer Transkriptionen von Texten aus Originalquellen wird künftig vollständig automatisiert. Waren die schrittweise digitalisierten Textquellen in Form von Bilddateien zwar weltweit zugänglich, so mussten sie doch erst durch Menschen gelesen und elektronisch transkribiert werden, bevor sie in Form von Volltexten weiterbearbeitet werden konnten. Doch wie lassen sich die Bilddateien softwaregestützt in prozessierbare Volltexte verwandeln? Unproblematisch ist die Optical Character Recognition (OCR)[28] einer Antiqua-Standard-Schrift, die moderne Drucke auszeichnet. Der überwiegende Anteil digitalisierter Schriftquellen und Textobjekte liegt jedoch handschriftlich oder in gebrochenen Druckschriften vor, die größte Varianz besitzen und nur mit komplexerer Transkriptionssoftware und Modellen der OCR oder Handwritten Text Recognition (HTR) zu bearbeiten sind.
Ziel der Texterkennung durch HTR/OCR ist es, die innerhalb der durch Scanner oder Digitalkameras produzierten Bilddigitalisate erfassten Buchstaben, Wörter und Sätze einer handschriftlichen oder gedruckten Buchseite zu erkennen, sie als bedeutungstragende Zeichen zu interpretieren und in maschinenlesbare Texte umzuwandeln. Diese Umwandlung von Bildern in Texte findet in komplexen Schritten statt: Nach einer Vorverarbeitung des Bilddigitalisats (Preprocessing mit Bildoptimierung, Binarisierung) für die Texterkennung findet zunächst eine Optical Layout Recognition (OLR) mit Identifizierung der Layoutelemente wie Textblöcke, Absätze, Überschriften, Grundlinien und Zeilen statt, anschließend werden die Einzelzeichen von einer Texterkennungs-Engine automatisch voneinander separiert, klassifiziert und ein Abgleich der identifizierten Worte mit einem Wörterbuch durchgeführt. Voraussetzung einer solchen automatischen Transkription ist jedoch die intellektuelle Vorbereitung und Kontrolle dieses Prozesses, indem zunächst eine Anzahl von Seiten der vorstrukturierten Bilddateien transkribiert wird. Auf Grundlage dieser so genannten Ground-Truth-Daten[29] werden Modelle trainiert, mit denen automatische Transkriptionen möglich werden. Abschließend wird das HTR/OCR-Ergebnis korrigiert, bevor eine Langzeitarchivierung der Transkriptionen in geeigneten Repositorien stattfindet.
Aktuelle Verfahren automatischer Texterkennung zielen auf die Entwicklung standardisierter Modelle, um möglichst vielfältige Schreibstile und Drucktypen zu erkennen. Eine Volltexterkennung gedruckter Texte mit der freien OCR-Software Tesseract[30] oder dem kommerziellen Abbyy FineReader[31] erzielt bereits hervorragende Ergebnisse.[32] Auf das Projekt OCR-D wird in Kapitel 1.3 eingegangen. Die Texterkennung für Handschriften basiert auf kommerzieller HTR-Software wie Transkribus oder dem Open Source-Programm eScriptorium.[36] Die Zukunftsvision, das gesamte in Handschriften und Drucken überlieferte schriftliche Kulturerbe, sofern es digitalisiert ist, automatisch lesbar zu machen, gewinnt bereits jetzt eine immer konkretere Gestalt, da Entwicklungen der Künstlichen Intelligenz (KI) aus unterschiedlichen Fachperspektiven vorangetrieben werden.
Um Konzepte und Instrumente der DH vollumfänglich auf das schriftliche Kulturerbe anzuwenden, müssen ihre Forschungsgegenstände, insbesondere die in historischen Quellen überlieferten Texte, vollständig digital verfügbar sein. Damit ist nicht nur die Herstellung digitaler Faksimiles gemeint, sondern die Transkription und Auszeichnung der Quellentexte in digitalen maschinenlesbaren Formaten einer Volltexttransformation.
In der digitalen Transformation textbasierter historischer Kulturwissenschaften müssen Texte nicht nur transitiv[37] sein, indem sie von ihren materiellen Trägern abgelöst und beliebig kopiert werden können, Texte müssen auch prozessierbar[38] sein, indem sie indexiert, durchsucht und mit Methoden der DH, beispielsweise in digitalen Editionen, bearbeitet und erforscht werden können. Dies ist erst dann möglich, wenn die auf Grundlage der Digitalisate intellektuell oder automatisch generierten Transkriptionen eine TEI/XML-Auszeichnung erhalten.[39]
Die digitale Transformation der Geistes- und Kulturwissenschaften benötigt leistungsfähige Informationsinfrastrukturen, zu denen auch Gedächtnisinstitutionen wie Bibliotheken gehören. Die Entwicklung historischer Volltextdatenbanken für Quellen und Forschungsliteratur ist häufig mit diesen Infrastrukturen verbunden. Gegenstand des folgenden Kapitels sind zentrale Institutionen, die gemeinsam mit maßgeblichen Autorinnen und Autoren sowie mit Verlagen relevante Projekte mit Bezug auf historische Volltextdatenbanken für Quellen und Forschungsliteratur tragen.[40]
Nach Bernhard Fabian[41] haben Bibliotheken für die Geisteswissenschaften eine vergleichbare Funktion, wie sie Labore für die Naturwissenschaften besitzen. Da es sich bei den von Bibliotheken bereitgestellten geisteswissenschaftlichen Ressourcen vornehmlich um Texte handelt, liegt eine Herausforderung historischen Arbeitens darin, mit textbasierten Forschungsressourcen und Nachweissystemen realer und virtueller Bibliotheken umzugehen, Texte zu finden, zu lesen, zu analysieren und zu interpretieren. Historische Volltextdatenbanken sind Teil dieser komplexen Textwelten.
Die bibliothekarische Infrastruktur in Deutschland gründet auf zwei Konzepten: Verteilte deutsche Nationalbibliothek und Verteilte nationale Forschungsbibliothek. Während die Verteilte deutsche Nationalbibliothek das gesamte deutsche schriftliche Kulturerbe als Quellen sammelt, katalogisiert, digitalisiert und bewahrt, verfolgt die Verteilte nationale Forschungsbibliothek dasselbe Ziel für die relevante Forschungsliteratur aus allen wissenschaftlichen Disziplinen – auch für die Geschichtswissenschaften. In beiden Fällen entstehen Volltextdatenbanken für Studium, Forschung und Lehre.
Sammlungen in Bibliotheken als Spiegel deutscher Geschichte
Die Verteilte deutsche Nationalbibliothek lässt sich unmittelbar aus der deutschen Geschichte herleiten. Im Gegensatz zu anderen Nationen wurde in Deutschland eine Nationalbibliothek erst 1912 gegründet, um als zentrale Archivbibliothek das schriftliche Kulturerbe in deutscher Sprache aus Deutschland und dem Ausland nicht nur zu sammeln, sondern als nationalbibliografisches Zentrum auch zu verzeichnen. Hierin liegt die Aufgabe der heutigen Deutschen Nationalbibliothek (DNB). Für das vorangegangene Jahrtausend mit seiner reichen Schriftkultur in Gestalt von Manuskripten und Drucken indessen ist der Nachweis der Überlieferung höchst disparat und durch die Geschichte der deutschen Territorien geprägt, aus der einzelne Bibliotheken mit besonderer Sammlungsgeschichte hervorgingen. Diesen wurde später für die Jahrhunderte vor 1912 die retrospektive Sammlung und Verzeichnung des deutschen schriftlichen Kulturerbes anvertraut (s.u.).
Handschriften
Die zentrale Quellengattung vormoderner historischer Epochen gründet in der reichen Klosterkultur, in der Texte erdacht, abgeschrieben und aufbewahrt wurden. Das Fenster in diese Welt der Manuskripte ist das Handschriftenportal (HSP), das 2023 Manuscripta Mediaevalia ablöste. Es weist Handschriften und Handschriftenfragmente aus Mittelalter und Neuzeit in deutschen Sammlungen zentral nach (vgl. Kap. 2.6). Im Hinblick auf das mittelalterliche Handschriftenerbe geht man von etwa 60.000 überlieferten Dokumenten aus. Als Forschungsinfrastruktur für das in deutschen Sammlungen aufbewahrte und im HSP präsentierte Handschriftenerbe haben sich sechs Handschriftenzentren an den national bedeutenden Altbestandsbibliotheken etabliert: Staatsbibliothek zu Berlin – Preußischer Kulturbesitz, Universitätsbibliothek Frankfurt am Main, Universitätsbibliothek Leipzig, Bayerische Staatsbibliothek München, Württembergische Landesbibliothek Stuttgart, Herzog August Bibliothek Wolfenbüttel.
Inkunabeln
Sind Handschriften als historische Quellen für einen Zeitraum von etwa eineinhalb Jahrtausenden von der Spätantike bis in die jüngste Zeitgeschichte relevant, so prägen Inkunabeln lediglich die kurze Epoche zwischen der Mitte des 15. und dem Beginn des 16. Jahrhunderts.[45] Mediengeschichtlich stehen sie zwischen Handschriften und Alten Drucken: Zwar überwanden die Inkunabeln mit ihrer technischen Innovation des Druckes mit beweglichen Lettern und der dadurch möglichen hundertfachen Vervielfältigung von Texten das handgeschriebene mittelalterliche Buch – im Hinblick auf Gestaltung und Layout blieb dieses jedoch noch mächtiges Vorbild, an dem sich die Inkunabeldrucker häufig bis ins Detail orientierten.
Schätzungen zufolge sind weltweit etwa 550.000 Exemplare von rund 30.000 unterschiedlichen Werken erhalten, darunter etwa 125.000 Exemplare in Deutschland.[46] Über die national und international relevanten Nachweissysteme und Volltextdatenbanken für Inkunabeln bietet Kapitel 2.6 einen detaillierten Überblick. Die historische Epoche der Frühen Neuzeit umfasst die mediengeschichtlichen Epochen der Inkunabeln und der Alten Drucke zwischen dem Ende der Handschriftenzeit Mitte des 15. Jahrhunderts und dem Beginn der industriellen Buchproduktion im Zeitalter der Industrialisierung im 19. Jahrhundert.
Alte Drucke des 16. bis 18. Jahrhunderts
Die Epoche der sogenannten Alten Drucke begann in dem Moment, als sich das gedruckte Buch nach dem Übergangsmedium der Inkunabel von seinem kulturellen Vorbild, der Handschrift, vollends zu emanzipieren begann. Die systematische Dokumentation und Sammlung der deutsch(sprachig)en Schriftkultur beruht auf unterschiedlichen Säulen: Auf der seit 1969 als Druckausgabe erstellten retrospektiven Nationalbibliografie für Drucke der Jahre 1501–1600 bauten seit 1996 die retrospektive Nationalbibliografie für Drucke der Jahre 1601–1700 (VD17) sowie seit 2009 die retrospektive Nationalbibliografie für Drucke der Jahre 1701–1800 (VD18) auf (vgl. Kap. 2).
Dieses System ist Grundlage der Verteilten deutschen Nationalbibliothek. Sie wird koordiniert durch die Arbeitsgemeinschaft Sammlung Deutscher Drucke (AG SDD), dem 1989 gegründeten Zusammenschluss der sechs bedeutendsten deutschen Altbestandsbibliotheken, die gemeinsam das gedruckte deutsche Kulturerbe sammeln, erschließen, digitalisieren und bewahren:
– 1450–1600: Bayerische Staatsbibliothek, München
– 1601–1700: Herzog August Bibliothek, Wolfenbüttel
– 1701–1800: Niedersächsische Staats- und Universitätsbibliothek, Göttingen
– 1801–1870: Universitätsbibliothek Johann Christian Senckenberg, Frankfurt am Main
– 1871–1912: Staatsbibliothek zu Berlin – Preußischer Kulturbesitz
– 1913ff.: Deutsche Nationalbibliothek, Leipzig und Frankfurt am Main
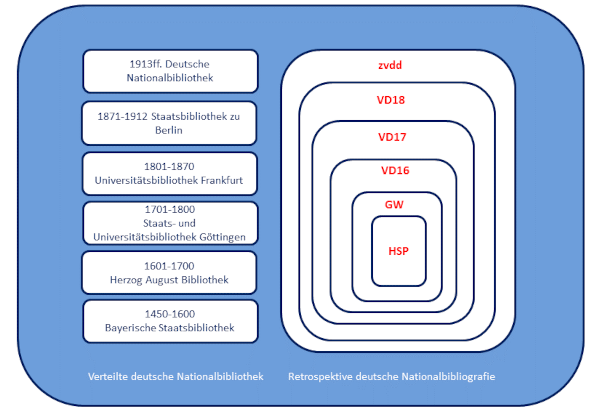
Abbildung 4. Verteilte deutsche Nationalbibliothek und retrospektive deutsche Nationalbibliografie
Die Idee einer Verteilten nationalen Forschungsbibliothek[51] entstand nach dem Zweiten Weltkrieg, als Studium, Forschung und Lehre an den Universitäten vor dem Hintergrund begrenzter Ressourcen effizient wieder aufgenommen werden sollten. Bereits damals war es keiner einzelnen deutschen Bibliothek möglich, die national und international publizierte Forschungsliteratur auch nur annähernd umfassend zu erwerben. Daher wurde 1949 das kooperativ organisierte Modell unterschiedlicher Sondersammelgebiete (SSGs) etabliert, durch das führende wissenschaftliche Bibliotheken mit Unterstützung der DFG sicherstellten, dass die relevanteste internationale Forschungsliteratur in Deutschland in mindestens einem gedruckten Exemplar zur Verfügung stand. Dieses konnte im Rahmen der überregionalen Literaturversorgung per Fernleihe deutschlandweit ausgeliehen werden. Die SSGs waren nicht nur printbasiert, sondern verfolgten auch eine forschungsunabhängige Erwerbungspolitik, um auch diejenigen Publikationen zu akquirieren, die erst künftiger Forschung dienen könnten.
Angesichts der digitalen Transformation in Wissenschaft und Bibliothek musste sich das etablierte kooperative System der überregionalen Literaturversorgung grundlegend wandeln. Die SSGs wurden seit 2015 zu Fachinformationsdiensten (FIDs) weiterentwickelt, die zwar weiterhin die lokalen Bibliotheken an Universitäten und Forschungseinrichtungen durch zentrale Erwerbung gedruckter Literatur ergänzen, die aber insbesondere auf die ortsunabhängige Versorgung der Wissenschaft mit digitalen Forschungsressourcen und Dienstleistungen auch für aktuelle Forschungstrends zielen. Die geschichtswissenschaftlichen SSGs stellen inzwischen ein reiches Portfolio von Volltextdatenbanken für Forschungsliteratur – und für Quellen – zur Verfügung. 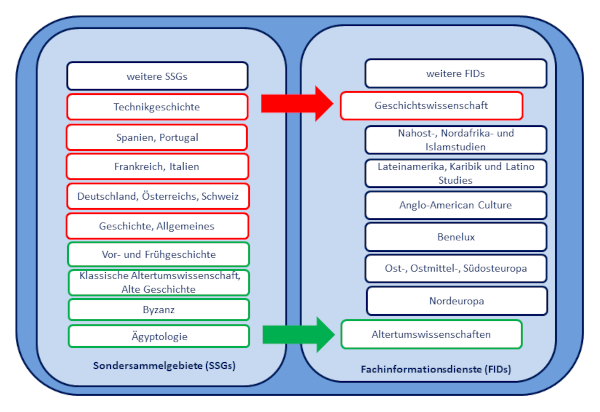
Abbildung 5. Verteilte nationale Forschungsbibliothek – Beispiele für die Umwandlung geschichtswissenschaftlicher SSGs zu FIDs
Im Folgenden wird die Entwicklung der Volltexterkennung (Kap. 1.1) in Bezug auf die Konzepte der Verteilten deutschen Nationalbibliothek und der Verteilten nationalen Forschungsbibliothek (Kap. 1.2) für historische Volltextdatenbanken für Quellen und Forschungsliteratur beschrieben. Dabei werden zunächst zentrale Institutionen vorgestellt, die relevante Projekte zu Digitalisierung, Volltexterkennung, Volltextdatenbanken und Digitalen Editionen tragen.
Die Philosophische Fakultät der Universität zu Köln gehört zu den führenden Standorten im Bereich digitale Geschichtswissenschaften und DH in Deutschland: Hier wurde in der Tradition der historischen Fachinformatik 1997 die Professur für Historisch-Kulturwissenschaftliche Informationsverarbeitung (HKI) eingerichtet, die von Manfred Thaller geprägt wurde, der auch den Prozess der Digitalisierung des schriftlichen Kulturerbes an Bibliotheken begleitete. Das Institut für Digital Humanities (IDH) widmet sich der historisch-kulturwissenschaftlichen und sprachlichen Informationsverarbeitung und arbeitet mit dem Data Center für Digital Humanities (DCH) zusammen, das Geisteswissenschaftlerinnen und Geisteswissenschaftler bei der Sicherung, Verfügbarkeit und Präsentation von Forschungsdaten und -ergebnissen berät. Es ist darüber hinaus an geisteswissenschaftlichen Konsortien der Nationalen Forschungsdateninfrastruktur (NFDI) beteiligt. Beide Institutionen sind Teil des 2009 gegründeten Cologne Center for eHumanities (CCeH), das als Kompetenzzentrum für DH-Projekte über Köln hinauswirkt.
Mit der Kölner Schule Thallers verbunden ist Patrick Sahle, der mit zahlreichen Publikationen und Projekten der DH[58] hervorgetreten ist und diesen Forschungsbereich an der Bergischen Universität Wuppertal vertritt.
Wie Köln besitzt das 1998 gegründete Kompetenzzentrum – Trier Center for Digital Humanities eine reiche Tradition. Mit diesem kooperiert das Fach Computerlinguistik und Digital Humanities im Fachbereich II Sprach-, Literatur- und Medienwissenschaften der Universität.
Neben Köln, Wuppertal und Trier besitzt die Westfälische Wilhelms-Universität Münster einen etablierten Schwerpunkt im Bereich der DH. Während das Center for Digital Humanities (CDH) einen Interessensverbund von digital Forschenden der Fachbereiche Geisteswissenschaften und Informatik bildet, bietet das Service Center for Digital Humanities (SCDH) konkrete Unterstützung bei Planung und Durchführung einschlägiger Projekte. Die institutionelle Einbindung des SCDH in die Universitäts- und Landesbibliothek Münster zeigt die enge Verbindung zwischen Bibliothek und Fachwissenschaften auf dem Feld der DH.
Aus einer ähnlichen Verbindung ist das Würzburger Zentrum für Philologie und Digitalität „Kallimachos“ (ZPD) hervorgegangen. Als zentrale wissenschaftliche Einrichtung der Universität verbindet es Geisteswissenschaften, Informatik und DH in hervorragender Weise, wie die hier entstandenen digitalen Editionen und Volltextdatenbanken zeigen.[67]
Ein Beispiel für ein außeruniversitäres Forschungsinstitut, das in DH-basierten Projekten über lange Erfahrungen verfügt, ist das Leibniz-Institut für Bildungsmedien|Georg-Eckert-Institut (GEI). Seine bis in das 17. Jahrhundert zurückgehende Sammlung historischer Schulbücher wird seit 2009 digitalisiert über die digitale Schulbuchbibliothek GEI-Digital publiziert.
Auf der Digitalisierung der Verzeichnisse deutscher Drucke des 16., 17. und 18. Jahrhunderts innerhalb der Verteilten deutschen Nationalbibliothek (Kap.1.2) setzt seit 2014 das Projekt OCR-D auf.[71] Da große Teile der Nationalbibliografien VD16, VD17 und VD18 inzwischen mit Volldigitalisaten angereichert sind, ist durch die Entwicklung im Bereich OCR eine Volltexttransformation des gesamten gedruckten deutschen schriftlichen Kulturerbes möglich geworden, indem aus den als Bilddateien gespeicherten Digitalisaten durchsuchbare Textdateien erzeugt werden: Die wissenschaftliche Nutzbarkeit digitalisierter Drucke insbesondere im Kontext der DH setzt zwingend maschinenlesbare Volltexte voraus. Künftig sollen innerhalb der digitalen Verteilten deutschen Nationalbibliothek nicht nur umfassende Volltextsuchen, sondern auch differenzierte Analysen und Bearbeitungen der Textquellen mit Werkzeugen der DH im distant reading möglich sein.
Mit der Open Source OCR-D-Software, deren Prototyp 2020 fertiggestellt wurde, können Modelle für eine automatische Transkription von Texten entwickelt werden, die mit der Vielfalt der historischen Layoutvarianten, der Drucktypen, der Orthographie und der Sprache umgehen können.
Um Technologien der automatischen Texterkennung möglichst niederschwellig einsetzen zu können, arbeitet das Zentrum für Philologie und Digitalität „Kallimachos“ (ZPD) gegenwärtig daran, in den Projekten OCR4all und OCR4all-libraries – Volltexterkennung historischer Sammlungen unterschiedliche freie OCR-Tools in einem standardisierten Workflow zusammenzuführen.
Sämtliche Projekte, die von universitären und außeruniversitären Instituten sowie von Bibliotheken konzipiert und realisiert werden, bedürfen einer zuverlässigen Finanzierung: Hierbei spielt der DFG-Förderbereich Wissenschaftliche Literaturversorgungs- und Informationssysteme (LIS) eine herausragende Rolle. Die DFG-geförderten Projekte und Forschungsinitiativen zu Digitalisierung und Volltexterkennung als Grundlage für die Entwicklung von Volltextdatenbanken dokumentiert die Datenbank GEPRIS.
Neben dem DFG-geförderten nationalen Projekt OCR-D wird die Forschung zum Thema Volltexterkennung auch auf Landesebene öffentlich unterstützt: Das an den Universitätsbibliotheken Mannheim und Tübingen angesiedelte Projekt OCR-BW beispielsweise hat zum Ziel, Bibliotheken, Universitäten und Forschende in Baden-Württemberg bei der Implementierung und Anwendung von automatischer Texterkennungs- und Transkriptionssoftware zu unterstützen.[77] Neben der Software OCR-D erforscht OCR-BW die Software-Lösungen und OCR-Engines Tesseract, OCRmyPDF, Ocropus, Kraken, Calamari, eScriptorium und Transkribus.
Zum Abschluss dieses Kapitels informieren wenige Hinweise darüber, wie man sich über aktuelle Themen, Projekte sowie wichtige Autorinnen und Autoren innerhalb des Fachdiskurses zu Volltextdatenbanken im Kontext digitaler Geschichtswissenschaften informieren kann. Relevant ist insbesondere die spezifische inhaltliche Perspektive: Handelt es sich um eine eher geschichtswissenschaftliche, informationswissenschaftliche oder bibliothekarische Fragestellung?
Aus geschichtswissenschaftlicher Sicht bietet der FID historicum.net einen der wichtigsten Rechercheeinstiege auch für Methoden und Werkzeuge der digitalen Geschichtswissenschaften. Der FID Buch-, Bibliotheks- und Informationswissenschaft (FID BBI) informiert über Spezialliteratur und Forschungsressourcen aus drei Kerndisziplinen, deren Anwendung auch in den digitalen Geschichtswissenschaften relevant sein können.
Während diese beiden Portale für die Recherche nach selbstständiger (Monografien) und unselbstständiger (Aufsätze) Literatur geeignet sind, bietet die Zeitschriftendatenbank (ZDB) einen vollständigen Überblick über die periodisch erscheinende Literatur der betreffenden Disziplinen.
Ein Beispiel ist die Zeitschrift für digitale Geisteswissenschaften (ZfdG). Sie bietet einen Einblick in den interdisziplinären Fachdiskurs der mit digitalen Ressourcen, Methoden und Konzepten arbeitenden Geisteswissenschaften, zu denen die Geschichtswissenschaften gehören.
Ein anderes Beispiel ist RIDE – A review journal for digital editions and resources mit einem Überblick über Konzepte und Technologien aktueller digitaler Editionen. In seiner Schriftenreihe (SIDE) behandelt das Institut für Dokumentologie und Editorik (IDE) die Anwendung innovativer Informationstechnologien für die Arbeit mit historischen Dokumenten und Texten. In Kooperation mit dem IDE und der Bergischen Universität Wuppertal wird von Patrick Sahle der Catalog of Digital Scholarly Editions herausgegeben, der eine gezielte Recherche nach digitalen Editionen ermöglicht.
Aktuelle Informationen über die Entwicklung historischer Volltextdatenbanken bietet auch der Blog des Verbandes DHd – Digital Humanities im deutschsprachigen Raum. Er entstand auf Initiative der Forschungsverbünde TextGrid und DARIAH-DE sowie des Max-Planck-Instituts für Wissenschaftsgeschichte Berlin.
Neben dem in Fachjournalen und Wissenschaftsblogs schriftlich geführten Fachdiskurs ist der direkte persönliche Austausch in Fachverbänden entscheidend. Für den Fachdiskurs in Deutschland am wichtigsten ist der 2012 an der Universität Hamburg gegründete Verband DHd – Digital Humanities im deutschsprachigen Raum. Dieser richtet jährliche Tagungen aus, ist Herausgeber der genannten Zeitschrift für digitale Geisteswissenschaften (ZfdG) und bearbeitet in zahlreichen Arbeitsgruppen zentrale Themen der DH – die AG OCR beispielsweise Volltextdatenbanken. Innerhalb des Verbands der Historiker und Historikerinnen Deutschlands (VHD) befasst sich die Arbeitsgemeinschaft Digitale Geschichtswissenschaft mit den Themen DH, Forschungsdaten, digitale Methoden oder digitale Quellenkritik.
Die vorausgegangene Skizze des State of the Art der Digitalisierung, digitalen Transformation und Methodenentwicklung in Bibliotheken und digitalen Geschichtswissenschaften zeigt, in welche Nutzungsszenarien historische Volltextdatenbanken eingebettet sind. Historische Volltextdatenbanken für Quellen und Forschungsliteratur werden als integrale Bestandteile offener, vernetzter Text- und Datenwelten verstanden, die über folgende Qualitäten verfügen sollten:
– Digitalisierung nach DFG-Standards.
– Beschreibung der Digitalisate durch Metadaten im Format METS/MODS für den Datenaustausch über APIs.
– Downloadmöglichkeit der Digitalisate mitsamt Roh- und Metadaten auf Grundlage der Prinzipien des Open Access, (Linked) Open Data sowie der FAIR-Prinzipien (findable, accessible, interoperable, reusable).
– Volltextindexierung und Volltexterkennung (HTR, OCR) für quantitative Volltextanalysen im distant reading, die ein qualitatives close reading auf eine neue Grundlage stellen.
– Publikation der Digitalisate im Open Access oder unter möglichst offenen Lizenzen zur Nachnutzbarkeit in Open Science-Szenarien.
– Referenzierbarkeit der Digitalisate durch stabilen Uniform Resource Name (URN) oder Uniform Resource Identifier (URI).
– Möglichkeit der Einbindung in virtuelle Forschungsumgebungen und (kollaborativen) Weiterverarbeitung der Digitalisate mit quantitativen und qualitativen Forschungsansätzen durch Tools und Methoden der DH (z.B. Annotationen, Visualisierungen).
– Möglichkeit vergleichenden Arbeitens, z. B. durch Verwendung des International Image Interoperability Framework (IIIF), um Digitalisate von Texten und Objekten institutionsübergreifend austauschen und standortunabhängig in unterschiedlichen Viewern präsentieren sowie mit Bildbearbeitungs- und Annotationstools bearbeiten zu können.
– Auffindbarkeit durch bibliothekarisch-formale und wissenschaftlich-intellektuelle Erschließung mit geeigneten normierten Metadaten.
– Vernetzung von Quellen und Forschungsliteratur miteinander.
Speziell für Volltextdatenbanken für historische Originalquellen wie Texte oder kulturelle Artefakte empfiehlt sich:
– Erschließung durch wissenschaftliche Beschreibungen (z.B. Kataloge).
– Verknüpfung mit Editionen (gedruckt, digital).
– Verknüpfung mit Forschungsliteratur (gedruckt, digital).
– Kontextualisierung mit weiteren relevanten Texten und Objekten (gedruckt, digital) in Fach- und Kulturportalen.
Speziell für Volltextdatenbanken für digitalisierte und genuin digitale Forschungsliteratur empfiehlt sich:
– Erschließung durch bibliothekarische Metadaten und Normdaten.
– Erschließung durch Thesauri, Fachklassifikationen oder intellektuelle Inhaltserschließung.
– Verknüpfung über Linkresolver mit lokalen Bibliothekskatalogen.
– Verknüpfung mit digitalisierten historischen Originalquellen.
Welche dieser Nutzererwartungen historische Volltextdatenbanken bereits erfüllen und wo weiterhin Entwicklungsbedarf besteht, wird im folgenden Kapitel exemplarisch gezeigt. 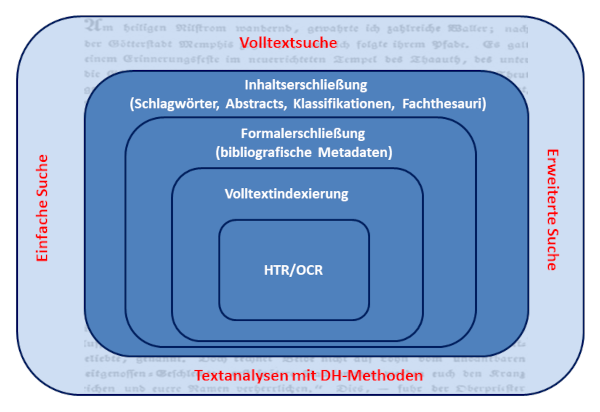
Abbildung 6. Möglichkeiten der Erschließung und Nutzung von digitalisierten Texten und Quellen in Volltextdatenbanken
Eine auch nur annähernd vollständige Bestandsaufnahme historischer Volltextdatenbanken kann im Rahmen dieses Guides nicht geleistet werden. Der praxisorientierte Überblick ist vor dem Hintergrund der Konzepte der Verteilten deutschen Nationalbibliothek und der Verteilten nationalen Forschungsbibliothek (Kap. 1.2) untergliedert nach Volltextdatenbanken für Forschungsliteratur (Kap. 2.5) einerseits, für Quellen und Quelleneditionen (Kap. 2.6) andererseits. Hinter beiden Konzepten stehen Institutionen, die mit konkreten historischen Volltextdatenbanken verbunden sind. Unterschieden wird ferner zwischen umfassenden Portalen und einzelnen Volltextdatenbanken. Die folgende Übersicht präsentiert schwerpunktmäßig Volltextdatenbanken für Quellen nach historischen Epochen, Regionen und Themen. Die diesen Guide ergänzende Linkliste beinhaltet weitere ausgewählte Ressourcen.
Wie in der Einführung (Kap. 1.1) beschrieben, sind historische Volltextdatenbanken in unterschiedlichen Kontexten entstanden und durch öffentliche Wissenschaftseinrichtungen und kommerzielle Verlage gleichermaßen geprägt: Bibliotheken beispielsweise bieten einerseits in Volltextdatenbanken digitalisierte oder genuin digitale Texte und Digitalisate von Quellen mitsamt Metadaten im Open Access an, sie finanzieren andererseits durch unterschiedliche Lizenzierungsmodelle den Zugang zu kommerziellen digitalen Produkten von Verlagen im Closed Access. Während Universitätsbibliotheken diese Ressourcen allein oder konsortial ausschließlich für ihre eigenen Forschenden, Lehrenden und Studierenden lizenzieren, ermöglichen Landes- und Staatsbibliotheken diese Zugänge für eine wissenschaftlich interessierte Öffentlichkeit außerhalb von Wissenschaftsinstitutionen.
Sowohl wissenschaftliche wie auch private Nutzerinnen und Nutzer in Deutschland profitieren von den Nationallizenzen. Die DFG finanzierte 2004 – 2010 den Erwerb von Lizenzen, um Studierenden, Wissenschaftlern und der interessierten Öffentlichkeit den freien Zugriff auf kostenpflichtige elektronische Verlagsprodukte zu ermöglichen. Die Nationallizenzen wurden 2011 durch Allianz-Lizenzen abgelöst, für die sich Bibliotheken in Konsortien zusammenfanden, um ausgewählte Datenbanken zu lizenzieren.
Etwas komplexer ist die Ablösung der Sondersammelgebiete (SSGs) durch Fachinformationsdienste (FIDs): Während auf die gedruckte Literatur der SSGs jedermann zugreifen konnte, sind die FID-Lizenzen nur für fachlich definierte Communities zugänglich (Kap. 1.2). Für die Geschichtswissenschaften sind mehrere Bibliotheken als Träger von Fachinformationsdiensten relevant, beispielsweise die Bayerische Staatsbibliothek für die Alte Geschichte, die Geschichte Deutschlands, Österreichs, der Schweiz, Frankreichs, Italiens und die Technikgeschichte in Kooperation mit dem Deutschen Museum (Abb. 5).
Die Situation, dass digitale Forschungsressourcen wie historische Volltextdatenbanken unterschiedlichen Zugangsmodalitäten unterliegen, bestimmt ihre Nutzung grundlegend und erfordert eine souveräne Orientierung auf diesem Feld. Da seit Beginn der Digitalisierung und der digitalen Transformation die gesellschaftliche Relevanz, die der freie Zugang zu wissenschaftlichen Informationen besitzt, immer deutlicher wurde, liegt in der weiteren Transformation hin zum Open Access eine der großen Herausforderungen der Zukunft.
So heterogen die analogen Vorläufer der historischen Volltextdatenbanken sind, so wenig eindeutig, ist eine Definition des Begriffs „Volltextdatenbank“. Aus geschichtswissenschaftlicher Praxis und informationstechnologischer sowie bibliothekarischer Theorie lässt sich dennoch ein gemeinsames Kernverständnis von Volltextdatenbanken herleiten. Im Allgemeinen sind Volltextdatenbanken Sammlungen elektronischer Volltexte mit bibliografischen und weiteren Metadaten. Historische Volltextdatenbanken im Speziellen sind Datenbanken, in denen für die Geschichtswissenschaften relevante einzelne Texte oder Sammlungen von Quellentexten, Quelleneditionen und Forschungsliteratur präsentiert werden. Als Volltextdatenbanken können aber auch Datenbanken für nicht-textuelle Quellen, Objekte und kulturelle Artefakte verstanden werden, sofern diese Textträger sind und von Transkriptionen begleitet werden. Beispiele hierfür sind Texte auf unterschiedlichen Trägern wie Stein, Papyrus, Pergament oder historische Karten. Dabei ist es unerheblich, ob die Texte lediglich als Images digitalisiert sind oder ob durch eine implementierte OCR-Erkennung eine Volltextsuche möglich ist.
Diese weite Definition möchte dem material turn innerhalb der Geschichtswissenschaften gerecht werden: (Text-) Objekte sind genauso wichtig wie reine Texte, denn auch sie vermögen durch ihr narratives Potenzial Geschichte zu erzählen – wenn sie von Historikerinnen und Historikern angemessen entziffert werden.
Objekte, bei denen Texte keinerlei Rolle spielen, werden hingegen in der Regel in Bilddatenbanken erfasst und spielen hier keine Rolle.
Das Datenbank-Infosystem (DBIS) ist das wichtigste Verzeichnis wissenschaftlicher Datenbanken im deutschen Sprachraum. 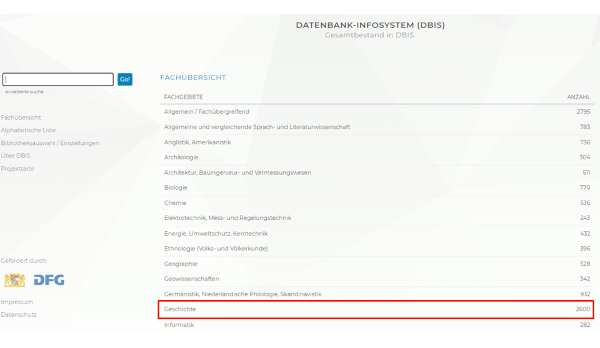
Abbildung 7. Datenbank-Infosystem (DBIS) – Fachübersicht (https://dbis.ur.de//fachliste.php?lett=l, 20.12.2023)
So heterogen die in DBIS verzeichneten Datenbanken sind, so gibt es doch formale Kriterien für die Aufnahme: Umfang der Datenmenge, langfristige Verfügbarkeit, kontinuierliche Pflege und Aktualisierung, Wissenschaftlichkeit, Seriosität der Inhalte und Herausgeber. In DBIS nicht aufgenommen werden Linklisten, Literaturlisten im HTML- oder PDF-Format, einzelne E-Books oder E-Journals sowie Bibliotheks-OPACs. DBIS ermöglicht sowohl eine bibliotheksübergreifende als auch eine lokale Sicht auf die Datenbanken sämtlicher Wissenschaftsdisziplinen und ihre Zugangsmodalitäten. Unter den etwa 2.600 Datenbanken allein für das Fach Geschichte finden sich knapp 1.060 historische Volltextdatenbanken – ein deutlicher Beleg für die kontinuierlich steigende Bedeutung von Volltextdatenbanken für das geschichtswissenschaftliche Arbeiten.
Unter die in DBIS als „Volltextdatenbank“ klassifizierten Produkten werden inhaltlich und formal heterogene Angebote subsumiert. DBIS versteht als „Volltextdatenbank“ eine „Datenbank jeglicher Art mit direkten Zugriffen auf Volltexte.“ Entsprechend dieser weiten Definition werden auch Portale, in denen Volltexte nur einen Teil des Angebotes darstellen, oder Datenbanken, die keine Texte, sondern audiovisuelle Medien beinhalten, subsumiert. Des Weiteren sind Vollständigkeit der Texte sowie ihre Erschließung durch Abstracts oder Schlagwörter zentrale Kriterien. In DBIS firmieren als „Volltextdatenbanken“ sowohl Datenbanken mit durch Metadaten erschlossenen Texten, die lediglich als Image-Digitalisate vorliegen, als auch Datenbanken mit digitalisierten Texten, die mit OCR-Software bearbeitet wurden und echte Volltextsuchen ermöglichen.
Ob in den von DBIS als Volltextdatenbanken für Quellen, Quelleneditionen und Forschungsliteratur klassifizierten Produkten eine Volltextsuche in den mit HTR/OCR bearbeiteten Bilddigitalisaten von Originalquellen (Inschriften, Handschriften, Inkunabeln, Drucke) oder digitalisierter Forschungsliteratur möglich ist, ist produktabhängig. Beispielsweise werden die Verzeichnisse der im deutschen Sprachraum erschienenen Drucke (VD16, VD17 und VD18) als „National- bzw. Regionalbibliografie“ klassifiziert, im Fall des VD17 jedoch zusätzlich als „Volltextdatenbank“. Eine Volltextsuche ist im VD17 jedoch in Zukunft erst dann möglich, wenn die Volltexttransformation der VD’s im Rahmen des Projektes OCR-D insgesamt realisiert ist. Ein anderes Beispiel ist die Datenbank IKAR-Landkartendrucke vor 1850, die als Fachbibliografie und zugleich als Volltextdatenbank klassifiziert ist, obwohl keine Volltextsuche in den Karten selbst möglich ist. Diese Beispiele zeigen, dass die Klassifizierung „Volltextdatenbank“ in DBIS uneinheitlich ist und keinen Rückschluss erlaubt, ob im Einzelfall tatsächlich eine Volltexterkennung durchgeführt wurde.
Mit der „erweiterten Suche“ lassen sich in DBIS gezielt Datenbank-Typen für unterschiedliche Fächer auswählen. Aus der Produktübersicht wird deutlich, unter welchem Lizenztyp eine Datenbank zur Verfügung steht: eine Ampelsymbolik kennzeichnet die unterschiedlichen Zugangsarten. 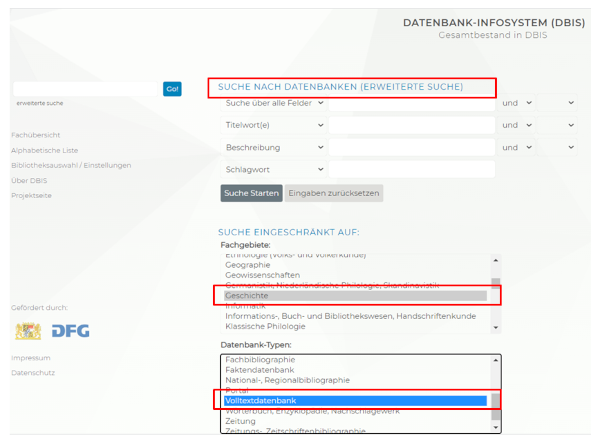
Abbildung 8. Datenbank-Infosystem (DBIS) – erweiterte Suche (https://dbis.ur.de//suche.php?bib_id=alle&colors=3&ocolors=40, 27.04.2024)
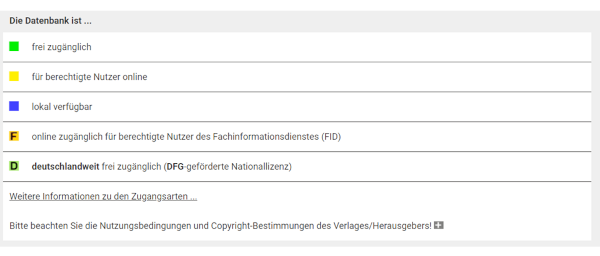
Abbildung 9. Datenbank-Infosystem (DBIS) – Zugangsarten und Ampelsymbolik (https://dbis.ur.de//dbliste.php?bib_id=ubfre&colors=31&ocolors=40&lett=a, 27.04.2024)
Nahezu sämtliche der im Folgenden besprochenen Produkte sind in DBIS verzeichnet, inhaltlich beschrieben und im Hinblick auf die institutionelle Lizenzierung definiert. Daher empfiehlt sich DBIS als erster Zugriff auf Volltextdatenbanken im Recherchealltag. Um die Lektüre dieses Überblicks zu erleichtern, wird sowohl in den Fußnoten als auch in der separaten Liste relevanter Volltextdatenbanken jedoch die direkte Verlinkung auf die Ressource präferiert.
Neben der Fachsicht innerhalb von DBIS empfiehlt sich für Historikerinnen und Historiker der Einstieg in die Fachinformationsrecherche über die jeweiligen FIDs als Teile der Verteilten nationalen Forschungsbibliothek. Diese tragen dafür Sorge, dass die relevanten Forschungsressourcen, zu denen auch die Volltextdatenbanken gehören, deutschlandweit zur Verfügung stehen. Hierdurch ergänzen sie das System der Nationallizenzen. Auch wenn die FID-Lizenzen für die Geschichtswissenschaften in DBIS erfasst sind, finden sich auf den Portalen der einzelnen FIDs vielfältige weitere Fachinformationen.
Für die Geschichtswissenschaften spielen Kulturportale sowie digitale Bibliotheken, die das kulturelle und wissenschaftliche Erbe öffentlich zugänglich machen, eine wichtige Rolle. Eine digitale Bibliothek verfolgt grundsätzlich dieselben Ziele wie eine papierene Bibliothek: Sammlung, Strukturierung, Erschließung und Archivierung von digital(isiert)en textuellen und kulturellen Inhalten.
Digitale Bibliotheken können zugleich Virtuelle Bibliotheken sein, die über keine eigenen Bestände verfügen, sondern als elektronisches Informationssystem Metadaten und Volltexte aus unterschiedlichen Quellen unter einer einheitlichen Oberfläche zusammenführen und recherchierbar machen. Im Folgenden werden die wichtigsten regionalen, nationalen und internationalen Kulturportale und digitale Bibliotheken mit dem Schwerpunkt auf historischen Schriftquellen vorgestellt.
Europeana, das Kulturportal Europas, setzt auf den nationalen Kultur- und Wissenschaftsinstitutionen mit ihren digitalisierten Sammlungen auf. Da die Erschließung heterogener Quellen unterschiedlicher Institutionen nicht immer homogen ist und nicht sämtliche Metadaten aus den Ursprungsdatenbanken in Europeana abgebildet werden, empfiehlt sich für qualitativ hochwertige Rechercheergebnisse immer auch eine differenzierte Suche in den Nachweissystemen der bestandshaltenden Institutionen selbst.
Die Deutsche Digitale Bibliothek (DDB) ist bei der Deutschen Nationalbibliothek (DNB) und der Stiftung Preußischer Kulturbesitz angesiedelt. Als nationales Portal weist sie das kulturelle Erbe deutscher Gedächtnisinstitutionen – beispielsweise Bücher, Archivalien, Bilder, Skulpturen, Tondokumente, Filme, Noten – zentral nach und stellt diese als nationaler Aggregator der Europeana zur Verfügung. Wie in der Europeana stehen in der DDB neben bibliografischen Metadaten auch Volltexte und Digitalisate zur Verfügung, die jedoch nicht immer für eine Volltexterkennung aufbereitet sind. Innerhalb der DDB weist das Archivportal-D digitalisiertes Archivgut, Findbücher und Informationen zu deutschen Archiven zentral nach.
Die DDB baut ihrerseits auf den Kulturportalen der Bundesländer auf, beispielsweise:
– Baden-Württemberg: LEO-BW – Landeskunde entdecken online.
– Bayern: bavarikon – Kultur und Wissensschätze Bayerns.
– Hessen: LAGIS – Landesgeschichtliches Informationssystem.
– Niedersachsen: Kulturerbe Niedersachsen.
– Sachsen: Sachsen.digital.
Insbesondere für die Regionalgeschichte sind diese Landesportale von großer Bedeutung, da sie häufig auch über unterschiedliche Themenportale verfügen.
Wie die DNB bieten auch Nationalbibliotheken anderer Länder übergreifende Portale und spezifische Angebote, in denen für die eigene nationale Geschichte relevante Quellen und Forschungsliteratur digitalisiert und in Volltextdatenbanken veröffentlicht werden. Für die historische Forschung lassen sich hier vielfältige Entdeckungen machen.
Nach dem Vorbild der Europeana entstand in den USA die Digital Public Library of America (DPLA) mit Digitalisaten von Kulturgütern aus Bibliotheken, Archiven und Museen der USA unter freien Lizenzen.
Die größte und bedeutendste Bibliothek der USA, die Library of Congress (LoC) in Washington, präsentiert in ihren Digital Collections zentrale Dokumente der US-amerikanischen Geschichte, darunter Handschriften, seltene historische Drucke und Bücher, Zeitungen, Karten, Noten, Ton- und Filmdokumente aus sämtlichen Bundesstaaten.
In Europa digitalisiert die British Library (BL) in London als größte Bibliothek der Welt nach der Library of Congress (LoC) ihre reichen Sammlungen und präsentiert diese in ihren Digital Collections– ein exzellenter Einstieg in die Recherche nach Schriftquellen wie Handschriften, Autographen, historischen Drucken, Büchern, Zeitungen, Karten, audiovisuellen Dokumenten und Forschungsliteratur zur Geschichte Englands und des Commonwealth.
Stellvertretend für die übrigen Nationalbibliotheken Europas sei die Bibliothèque nationale de France (BnF) in Paris genannt, die im Projekt Gallica gemeinsam mit zahlreichen Partnerinstitutionen eine digitale Bibliothek für das Kulturerbe Frankreichs aufbaut, das zu großen Teilen bereits im Volltext durchsuchbar ist – ein ausgezeichneter Einstieg in die französische Geschichte.
Neben diesen regionalen, nationalen und internationalen Kulturportalen gibt es zahlreiche digitale Bibliotheken mit speziellen Volltextdatenbanken, die für historische Forschungen von Interesse sein können. Als älteste digitale Bibliothek der Welt gilt das 1971 begründete Project Gutenberg, das zum Ziel hat, urheberrechtsfreie Bücher mit literarischen Texten weltweit zugänglich zu machen. Wurden am Beginn des Projekts ausgewählte Bücher von Freiwilligen manuell abgetippt und die Transkriptionen korrigiert, bevor diese im Internet veröffentlicht wurden, ermöglichte die kontinuierliche Verbesserung von Scan-Technik und Texterkennungssoftware ein immer schnelleres Wachstum dieser digitalen Bibliothek. Während im Project Gutenberg vorwiegend englischsprachige Bücher enthalten sind, bietet das Projekt Gutenberg-DE gemeinfreie deutschsprachige literarische Werke.[119]
Unter den kommerziellen Anbietern digitaler Bibliotheken auch historischer Bücher, in denen Volltextsuchen möglich sind, ist Google Books am bekanntesten. Mit seiner 1997 online gegangenen Suchmaschine wollte Google nicht nur die Informationen des World Wide Web erschließen. Die Idee des parallel entwickelten Library Projects war, das weltweite gedruckte kulturelle Erbe der „Gutenberg-Galaxis“ mit seinem darin niedergelegten menschlichen Wissen systematisch zu digitalisieren, mit OCR zu bearbeiten und eine globale Volltextsuche über sämtliche Textgattungen und Epochen zu spannen. Im Unterschied zum Ziel der Arbeitsgemeinschaft Sammlung Deutscher Drucke (AG SDD), das schriftliche Kulturerbe an deutschen Bibliotheken systematisch zu erfassen und zu digitalisieren, war Googles Ziel ein globales. Daher kooperierte der Internetkonzern einerseits mit kommerziellen Verlagen, andererseits mit wissenschaftlichen Bibliotheken weltweit – im deutschen Sprachraum mit der Österreichischen Nationalbibliothek Wien, mit der Bayerischen Staatsbibliothek München und mit der Staatlichen Bibliothek Regensburg. Google stellte die Digitalisate her – die Bibliotheken erhielten von Google eine digitale Kopie eines jeden gescannten Buches aus ihren Sammlungen.
Das von Google von Anfang an verfolgte Ziel ist jedoch nicht ohne Hindernisse zu erreichen – zu komplex ist die urheberrechtliche Situation im Falle der jüngeren Texte. Hierin liegt der Grund, dass lediglich ältere Bücher, deren urheberrechtlicher Schutz erloschen ist, frei zugänglich sind, während in allen anderen Fällen ein stark eingeschränkter Zugriff auf die Volltexte möglich ist: Google Books unterscheidet daher zwischen „Vollansicht“, „Eingeschränkte Vorschau“, „Auszugsansicht“ und „Keine Vorschau verfügbar“. Im Jahr 2019 gab Google Books anlässlich seines 15-jährigen Bestehens bekannt, mehr als 40 Millionen Bücher in mehr als 400 Sprachen digitalisiert zu haben.
Auf Grundlage dieses monumentalen Volltextcorpus lassen sich vielfältige quantitative Analysen durchführen. Mit dem Google Books Ngram Viewer beispielsweise lässt sich erkennen, wann ein bestimmter Begriff innerhalb von Google Books erstmals fassbar wird und wie sich seine Verwendung im Laufe der Zeit verändert hat.
Am Beispiel von Google Books werden zugleich die Grenzen einer wissenschaftlichen Recherche lediglich auf Grundlage einer Volltextsuche in Texten mit Volltextindexierung deutlich. Google hatte seine Suchmaschinentechnologie, die auf der Indexierung des World Wide Web beruhte, auf das digitalisierte gedruckte schriftliche Kulturerbe übertragen. Da eine systematische, bibliothekarische und wissenschaftliche Erschließung der einzelnen, von Google digitalisierten Bücher fehlt, muss eine Recherche in Google Books mit einer Stichwortsuche auskommen. Die gewählten Suchbegriffe sollten in unterschiedlichen Sprachen formuliert werden, um Zugriff auf die jeweils nationale Literatur zu erhalten.
Hier bieten Bibliotheken noch immer einen deutlichen Mehrwert: Sie verfügen über fachnahe Konzepte der qualitativen Strukturierung von Informationen und erschließen ihre Texte mit differenzierten Metadaten wie Schlagwörtern oder Fachthesauri, die für wissenschaftliche Recherchen notwendig sind. Die Verknüpfung mit Normdaten ermöglicht eine gezielte Referenzierbarkeit und Vernetzung von Texten, Objekten oder Daten. Insofern bietet Google Books zwar eine attraktive Ergänzung zu geschichtswissenschaftlichen Volltextdatenbanken, doch sollte man sich auch der Grenzen bewusst sein. Unter dem Aspekt der Sichtbarkeit des globalen kulturellen und wissenschaftlichen gedruckten Erbes innerhalb digitaler Bibliotheken ist zu beachten, dass eine Recherche mit der Suchmaschine Google unter Berücksichtigung von Google Books ein Ranking der Ergebnisse zeigt, in dem englischsprachige Literatur dominiert. Daher empfiehlt sich die gleichzeitige Konsultation von Kulturportalen und digitalen Bibliotheken wie der Europeana oder der DDB.
Wikisource, eine Sammlung gemeinfreier oder unter einer freien respektive Creative-Commons-Lizenz (CC-BY bzw. CC-BY-SA) stehender Texte, wird häufig unbewusst genutzt, da diese mit Wikipedia verbunden ist. Für die Geschichtswissenschaft ist Wikisource von besonderer Bedeutung, da insbesondere ältere Texte mit dem Status von historischen Quellen Berücksichtigung finden. Grundlage der in Wikisource präsentierten Texte sind Erstausgaben, Ausgaben letzter Hand oder kritische Editionen, so dass wissenschaftliche Qualität gewährleistet ist. Aber auch digitalisierte geschichtswissenschaftliche Zeitschriften und zahlreiche Volltexte gehören zu den Ressourcen für Historikerinnen und Historiker.
Nicht nur eine digitale Bibliothek für Volltexte von Büchern, Musik, Filmen, Software oder Bildern, sondern zugleich ein Dienst, der Webseiten in unterschiedlichen Versionen speichert, ist das 1996 gegründete gemeinnützige Internet Archive. Da es nicht möglich ist, das gesamte World Wide Web in allen Zuständen dauerhaft zu archivieren, bietet die Speicherung von „Momentaufnahmen“ dennoch einen breiten Zugriff auf Webseiten, die zeitweise im Internet verfügbar waren – dieser erfolgt mit Hilfe der Wayback Machine. Ein Spiegelserver des in San Francisco ansässigen Internet Archive findet sich übrigens in der Bibliotheca Alexandrina in Ägypten, am Ort der größten Bibliothek der antiken Welt.
Innerhalb des Million Book Project als Teilprojekt des Internet Archive werden gemeinfrei gewordene Bücher digitalisiert und in der Open Library publiziert. Hier soll in einem kollaborativen Ansatz jedes jemals publizierte Buch auf einer eigenen Webseite dokumentiert werden. Dabei kann zum gemeinfreien bibliografischen Nachweis auch der direkte Zugriff auf das Digitalisat mit dem Volltext treten. Im Unterschied zu Google Books mit der Digitalisierung auch urheberrechtlich geschützter Literatur konzentriert sich die Open Library auf gemeinfreie Bücher.
Ein gemeinsames Projekt von zahlreichen US-amerikanischen Universitätsbibliotheken sowie Forschungseinrichtungen aus der ganzen Welt ist die HathiTrust Digital Library. Bibliografische Datenbank und Repositorium digitalisierter Bücher zugleich, ist eine Volltextsuche in Millionen Dokumenten unterschiedlicher Fachbereiche möglich – die Geschichtswissenschaft bildet einen Schwerpunkt. Der aus dem Hindi und Urdu stammende Name „Hathi“ bedeutet übrigens „Elefant“: Diesem wird ein besonderes Gedächtnis nachgesagt – insofern gleicht er den Archiven und Bibliotheken als Gedächtnis der Menschheit.
Eine wichtige deutschsprachige Volltextbibliothek ist Zeno.org. Sie basiert auf der kommerziellen Reihe Digitale Bibliothek (CD’s, DVD’s) und umfasst Texte vom Anfang des Buchdrucks bis zum Beginn des 20. Jahrhunderts. Seit 2009 ist die Volltextsammlung Teil des Repositoriums von TextGrid, der Virtuellen Forschungsumgebung für die Geisteswissenschaften, und kann zur wissenschaftlichen Bearbeitung, beispielsweise in digitalen Editionen, genutzt werden.
Insbesondere für kulturgeschichtliche Fragestellungen relevant ist das Deutsche Textarchiv (DTA) als Referenzcorpus der neuhochdeutschen Sprache. Es umfasst etwa 1.500 sorgfältig ausgewählte und nach Erstausgaben digitalisierte Texte unterschiedlicher Disziplinen aus dem 17.–20. Jahrhundert. Im Konsortium Text+ der Nationalen Forschungsdateninfrastruktur (NFDI) ist das DTA als Repositorium und strukturiertes, linguistisch annotiertes Volltextcorpus historischer Texte eingebunden.
Ein Blick in die Welt der Archive und Museen rundet den Blick auf die für die Geschichtswissenschaften relevante Anbieter digitaler Bibliotheken und Volltextdatenbanken ab. Von nationaler Bedeutung für das deutsche Archivwesen ist das Bundesarchiv, die für Sicherung des Archivgutes der Bundesrepublik Deutschland und seiner Vorgängerstaaten zuständige Institution. Über seine (Volltext-) Datenbanken für Bilder, Filme, Töne und Karten ist die Recherche innerhalb der allgemeinen wie auch der speziellen Archivbestände möglich. Die beiden zentralen historischen Museen der Bundesrepublik Deutschland – das Deutsche Historische Museum (Berlin) und das Haus der Geschichte (Bonn) – präsentieren nicht nur Dauerausstellungen aus eigenen Beständen und zahlreiche Sonderausstellungen mit Leihgaben zu Themen der deutschen Geschichte. Ein gemeinsames Projekt beider Museen mit dem Bundesarchiv ist das Lebendige Museum Online (LeMO), in dem auch (Volltext-) Datenbanken eine zentrale Rolle spielen.
Lag der Fokus bis hierher auf retrodigitalisierten Texten, die für die Geschichtswissenschaft als ältere, gemeinfreie Forschungsbeiträge oder als Quellen interessant sein können, so wird im folgenden Kapitel ein kurzer Überblick über Volltextdatenbanken aktueller geschichtswissenschaftlicher Forschungsliteratur gegeben. 
Abbildung 10. Kulturportale und digitale Bibliotheken (Auswahl)
Portale und Volltextdatenbanken für Forschungsliteratur können hier nicht in der notwendigen Breite thematisiert werden. Hinweise zu relevanten Volltextdatenbanken finden sich in den Guides zu Epochen oder Regionen. Daher sei nur kursorisch auf wenige große fachübergreifende Ressourcen hingewiesen.
Eine der wichtigsten Volltextdatenbanken für Zeitschriften aus dem gesamten Spektrum der Geistes-, Kultur- und Sozialwissenschaften aus dem Zeitraum 1800–2000 ist das Periodicals Archive Online (PAO). Es bietet über eine differenzierte Recherchemaske den Zugriff auf 3 Millionen durch Abstracts erschlossene Artikel aus 700 Zeitschriften.
Unverzichtbar für die Recherche nach Fachartikeln internationaler Zeitschriften nicht nur aus den Geschichtswissenschaften ist die Volltextdatenbank Journal Storage (JSTOR). Enthalten sind internationale wissenschaftliche Zeitschriften vom ersten Jahrgang an – je nach Titel und lokaler Lizenz ist der Zugriff auf die aktuellen Hefte aufgrund einer moving wall nicht möglich. Das deutsche Pendant zu JSTOR ist das Volltextarchiv DigiZeitschriften mit deutschsprachigen Fachzeitschriften, unter denen die Geschichtswissenschaften mit etwa 350 Traditionszeitschriften vertreten sind.
Zu fachspezifischen Volltextdatenbanken bieten die einschlägigen FIDs, wie Propylaeum für die Alte Geschichte oder historicum.net für die mittlere und neuere Geschichte, weitere Hinweise. Auf fachübergreifende Ressourcen wie Google Books, das Internet Archive oder Hathi Trust und andere wurde bereits hingewiesen (Kap. 2.4). Weitere Hinweise finden sich in der kommentierten Linkliste Volltextdatenbanken.
Neben der Verteilten nationalen Forschungsbibliothek ist die Verteilte deutsche Nationalbibliothek Anbieter und Plattform historischer Volltextdatenbanken für Quellen und Quelleneditionen. Die nationalbibliografischen Verzeichnisse VD16, VD17 und VD18 sowie das zvdd sind vor allem für die deutsche Geschichte interessant – insbesondere durch die Perspektive ihrer geplanten Volltexttransformation im Rahmen des Projektes OCR-D. Die im Folgenden vorgestellten Volltextdatenbanken für historische Quellen berücksichtigen Produkte im Open wie im Closed Access.
Volltextdatenbanken für Quellen entstanden und entstehen dadurch, dass schriftbasierte Originalquellen wie Inschriften, Papyri, Handschriften oder Drucke digitalisiert und als Bilder in Datenbanken veröffentlicht werden. Im strengen Sinn handelt es sich in diesen Fällen aber zunächst (noch) nicht um „Volltextdatenbanken“ – die Quellen werden lediglich durch detaillierte Metadaten beschrieben. Erst die Entwicklung der Texterkennung für Handschriften (HTR) oder Drucke (OCR) ermöglicht im nächsten Schritt, aus den reinen Bilddigitalisaten echte Volltexte zu generieren, in denen recherchiert werden kann und deren Weiterverarbeitung innerhalb von DH-Szenarien möglich ist.
Mit Volltextdatenbanken digitalisierter Originalquellen sind Volltextdatenbanken für Quelleneditionen verbunden – vielfach werden diese nicht nur untereinander, sondern auch mit bibliografischen Datenbanken oder Volltextdatenbanken für Forschungsliteratur vernetzt.
Antike Textquellen können auf unterschiedlichen Trägern überliefert sein, beispielsweise in Stein gehauen als Inschriften oder handgeschrieben auf Papyri oder Pergament in Form von Rotuli oder Codices. Relevante Quellen für die Alte Geschichte sind jedoch nicht allein Textzeugnisse, sondern auch kulturelle Artefakte wie archäologische Funde.
Zentrales Rechercheportal für bibliografische Informationen, Beschreibungen, Digitalisate, Transkriptionen und Übersetzungen von Papyri, Ostraka oder Holztafeln aus bedeutenden internationalen Sammlungen ist papyri.info. Der Papyrological Navigator (PN) ermöglicht eine integrierte Recherche innerhalb unterschiedlicher Datenbanken, beispielsweise im Heidelberger Gesamtverzeichnis der griechischen Papyrusurkunden Ägyptens, in der Duke Databank of Documentary Papyri (DDbDP) und im Advanced Papyrological Information System (APIS). Letzteres weist Informationen (Bibliografien, Beschreibungen), Abbildungen (Digitalisate) oder Übersetzungen zu papyrologischen Materialien (Papyri, Ostraka, Holztafeln) aus internationalen Sammlungen nach.
Einen Überblick über die wichtigsten Papyrussammlungen Deutschlands bietet das Papyrus Portal. Es ermöglicht sowohl eine parallele Suche über einzelne Papyrus-Datenbanken als auch den Wechsel in lokale Präsentationen mit häufig differenzierteren Rechercheoptionen.
Epigraphische Textzeugnisse der Antike werden als archäologische Objekte ebenfalls in Volltextdatenbanken publiziert, die neben Beschreibungen der Inschriften mit spezifischen Metadaten auch Transkriptionen, Übersetzungen und Digitalisate umfassen. Ein Beispiel ist die Epigraphische Datenbank Heidelberg (EDH), die auf eine umfassende Dokumentation lateinischer und bilinguer (z.B. lateinisch-griechischer) Inschriften des Römischen Reiches zielt. Berücksichtigt werden insbesondere die außerhalb der großen Corpora publizierten Inschriften. Die Suchmaske ermöglicht eine differenzierte Recherche innerhalb des umfangreichen Materials – Inschriftentexte, Fotodokumentationen, Bibliografie und Geografie. Partner der EDH sind unter anderen die Epigraphik-Datenbank Claus/Slaby (EDCS), das Corpus Inscriptionum Latinarum (CIL),[150]Inscriptiones Graecae (IG), Searchable Greek Inscriptions (PHI Greek Inscriptions), Trismegistos (TM), Europeana EAGLE oder Ubi Erat Lupa (Lupa). Es ist zu beachten, dass papyrologische und epigraphische Quellen häufig in gemeinsamen Volltextdatenbanken erfasst sind.
Perseus Digital Library (PDL) ist eine der ältesten online verfügbaren geisteswissenschaftlichen Textsammlungen – mit Schwerpunkt auf der antiken Überlieferung. In der Kollektion Greek and Roman Materials bietet sie auf Grundlage zitierfähiger Editionen Volltexte klassischer griechischer und lateinischer Literatur, teilweise mit (englischen) Übersetzungen, die im Scaife Viewer miteinander verglichen werden können. Insbesondere Analysen historischer Begrifflichkeiten oder philologische Fragestellungen zum Wortgebrauch sind möglich.
Der Thesaurus Linguae Graecae (TLG) enthält klassische griechische Texte aus der Zeit zwischen etwa 800 v. Chr. und 600 n. Chr. sowie mittelalterliche historiographische, lexikographische und scholastische griechische Texte aus der Zeit zwischen etwa 600 n. Chr. und 1453 n. Chr. Die Suchmaske erlaubt komplexe Recherchen nach Autor, Werk, Datierung, Gattung, aber auch eine Volltextsuche innerhalb der Werke eines oder mehrerer Autoren. Die Darstellung der Texte erfolgt wahlweise in griechischen oder transliteriert in lateinischen Buchstaben. Die Verknüpfung der Texte des TLG mit weiteren Volltextdatenbanken für Quellen (PDL) oder für Forschungsliteratur (JSTOR) ermöglicht vernetztes digitales Arbeiten mit griechischen Textquellen für die Alte Geschichte.
Die Library of Latin Texts Complete Plus umfasst die beiden zuvor separaten Datenbanken Library of Latin Texts – Series A (LLT-A) und Series B (LLT-B). Inkludiert sind inzwischen mehr als 5.400 Werke von etwa 1.300 Autoren von den Anfängen der lateinischen Literatur im 3. Jh. v. Chr. bis zum 2. Vatikanischen Konzil (1962–1965): römische Klassiker, Kirchenväter, mittelalterliche lateinische Literatur sowie Texte der Reformation und Gegenreformation. Volltextsuche und Textanalyse ermöglichen vielfältige philologische Fragestellungen.
Die Sammlung Tusculum Online basiert auf der traditionsreichen Buchreihe mit inzwischen mehreren Hundert Bänden. Sie umfasst Editionen, Übersetzungen und Kommentare der griechischen und lateinischen Klassiker der Antike, künftig auch spätantiker, christlicher, byzantinischer und neulateinischer Literatur, basierend auf den teilweise vergriffenen Druckausgaben. Im Gegensatz zur Library of Latin Texts Complete Plus ist in der Sammlung Tusculum Online jedoch keine textübergreifende Volltextsuche möglich, sondern nur in den einzelnen Texten.
Ein umfassendes Informationssystem für die interdisziplinären altertumswissenschaftlichen Disziplinen ist das Portal iDAI.objects (Arachne) des Deutschen Archäologischen Instituts (DAI). Es ist eingebettet in eine modulare Forschungsinfrastruktur, die Objekte, Bücher, Bilder, bibliografische Daten und Forschungsdaten sowie Digitalisate nach einem einheitlichen Datenmodell verwaltet. Für geschichtswissenschaftliches Arbeiten, das sich auf eine breite Vielfalt altertumswissenschaftlicher Quellen stützen möchte, bieten sich hier herausragende Voraussetzungen.
Monumentale Editionen des quellenverliebten 19. Jahrhunderts zur Patrologie- und Mittelalterforschung sind die Patrologia Graeca (PG), die Patrologia Latina (PL) sowie die im folgenden Abschnitt zum Mittelalter besprochenen Monumenta Germaniae Historica (MGH). Die PG basiert auf der Patrologia Graeco-Latina, die von Jacques-Paul Migne zwischen 1857 und 1866 in 161 Bänden herausgegeben wurde.[165] Sie enthält zentrale Werke der christlich-griechischen Kirchenliteratur spätantiker und mittelalterlicher Theologie, Philosophie und Geschichte aus der Zeit zwischen 100 n. Chr. und 1478 und ist grundlegend für historische Forschungen zum frühen Christentum. Die Volltexterschließung erfolgt durch ein lateinisches und griechisches Inhaltsverzeichnis, einen Autoren-, Werktitel- und Sachindex.
In Ergänzung zur PG steht die PL, die Edition des lateinischen Schrifttums der Kirche von den Anfängen bis ins Hochmittelalter in insgesamt 221 Bänden, die Jacques-Paul Migne in zwei Reihen zwischen 1844 und 1855 publiziert hat.[166] Auf dieser Ausgabe beruht die Datenbank, die differenzierte Volltextsuchen ermöglicht. Texte der PL sind auch Bestandteil der Library of Latin Texts.[167]
Zu den zentralen Quellen für die Mediävistik gehören handschriftliche Urkunden, historiographische oder literarische Texte, Inschriften sowie kulturelle Artefakte. Da diese in Archiven, Bibliotheken oder Museen aufbewahrt werden, ist die Kenntnis institutioneller Infrastrukturen hilfreich. Ihre Sammlungen sind häufig Grundlage von Digitalisierungsprojekten und (Volltext-) Datenbanken, die digital vernetztes Arbeiten mit Methoden und Tools der Digital Humanities ermöglichen.
Einen hervorragenden Einstieg in die Überlieferung urkundlicher Quellen bietet Monasterium (MOM), das virtuelle Urkundenarchiv Europas. Es präsentiert etwa 500.000 digitalisierte Dokumente aus mehr als 60 europäischen Archiven – beispielsweise Bilder, Regesten, ältere gedruckte sowie neue Editionen. Eine Volltextsuche innerhalb der Metadaten, aber auch in transkribierten Urkunden, ist möglich.
Die seit dem 19. Jahrhundert entstandenen Handschriftenkataloge einzelner Bibliotheken sind unverzichtbare Instrumente der Text- und Überlieferungsgeschichte. Seit Beginn der Digitalisierung wurden Handschriftenkataloge und Handschriftenoriginale schrittweise digitalisiert und sind Grundlagen von Volltextdatenbanken.
Einen Überblick über das Handschriftenerbe im deutschsprachigen Raum bietet die Recherche in digitalen Handschriftenbibliotheken Deutschlands, Österreichs und der Schweiz. In Deutschland ist das Handschriftenportal (HSP) zentrale Informationsinfrastruktur für europäische Buchhandschriften in deutschen Sammlungen. Recherchierbar sind neben den bibliothekarischen Metadaten der Originale die wissenschaftlichen Beschreibungen der maßgeblichen Handschriftenkataloge. Zugleich ist das HSP zentrales Portal der Handschriftendigitalisate, die sich in den digitalen Bibliotheken der jeweiligen besitzenden Einrichtungen befinden. Durch Technologien wie IIIF erfüllt das HSP internationale Standards der wissenschaftlichen Arbeit mit Digitalisaten. Die dynamische Entwicklung automatischer Volltexterkennung mit HTR lässt Volltextsuchen innerhalb des Handschriftenerbes im HSP vorstellbar werden.
Für die Erforschung der Handschriftenüberlieferung in Österreich koordiniert das Institut für Mittelalterforschung der Österreichischen Akademie der Wissenschaften den Aufbau des Portals manuscripta.at – mittelalterliche Handschriften in Österreich. Sein Ziel, verstreute, schwer zugängliche Daten zu österreichischen Handschriften als Verweise, Links, Images oder Volltexte gebündelt zu präsentieren, macht manuscripta.at dem deutschen Handschriftenportal vergleichbar.
Das schweizerische Pendant e-codices – virtuelle Handschriftenbibliothek der Schweiz erschließt die mittelalterlichen und neuzeitlichen Handschriften aus öffentlichen, kirchlichen und privaten Sammlungen der Schweiz. Als Nationalbibliografie und Bestandsverzeichnis zugleich bietet e-codices den Zugriff auf wissenschaftliche Beschreibungen und digitale Reproduktionen der Handschriften. Es besteht die Möglichkeit, kollaborativ Annotationen oder bibliografische Angaben den einzelnen Handschriften hinzuzufügen.
Neben e-codices weist e-manuscripta.ch digitalisierte handschriftliche Quellen aus Schweizer Bibliotheken und Archiven nach: Texthandschriften (Einzel- und Sammelhandschriften), Briefe, Musikalien, Karten und Bilder. Gemeinsame Transkriptionsarbeit durch moderiertes Crowdsourcing ermöglicht schrittweise eine intellektuelle Volltexttransformation des Handschriftenerbes in der Schweiz – Grundsätze des Open Access und einer Citizen Science verbinden sich harmonisch.
Im Unterschied zu den genannten Portalen, die insbesondere das in Gedächtnisinstitutionen der Schweiz aufbewahrte Handschriftenerbe nachweisen, unterstützt Fragmentarium – Laboratory for Medieval Manuscript Fragments die praktische Forschung und Arbeit mit Handschriftenfragmenten, die internationale „digitale Fragmentologie“.
Ergänzend zu den nationalen Handschriftenportalen im deutschsprachigen Raum bietet der Handschriftencensus (HSC) einen Überblick über sämtliche deutschsprachige Handschriften des Mittelalters aus dem Zeitraum 750–1520 in internationalen Sammlungen. Das umfassende Bestandsverzeichnis bietet differenzierte Informationen und Metadaten zu mittelalterlichen Autoren, Werken und ihrer Überlieferung. Zu jedem Textzeugen ist nicht nur die relevante Literatur bibliografisch erfasst, sondern auch das Digitalisat verlinkt.
Für die Geschichte des Mittelalters bieten klassische Printeditionen die Grundlage von Volltextdatenbanken und komfortable Möglichkeiten des Zugriffs auf Quellen. Unentbehrlich sind die Monumenta Germaniae Historica (MGH) als grundlegende Sammlung von Quelleneditionen (Historiographie, Rechtstexte, Urkunden, Briefe, Dichtung) aus dem Zeitraum 500 – 1500, in der seit 1819 in mehr als 300 Bänden etwa 1.300 Texte erschienen sind. Die aktuellen gedruckten Editionen werden mit einer moving wall von drei Jahren digitalisiert und online publiziert. Differenzierte Suchoptionen ermöglichen einen umfassenden Volltextzugriff auf diese wichtigste Editionsreihe von Quellen zur mittelalterlichen Geschichte Deutschlands und Europas.
Ursprünglich als Vorarbeit zu den MGH konzipiert, entstand mit den Regesta Imperii (RI) ein weiteres Monument der Wissenschaftsgeschichte, das seit seiner Begründung 1839 für Historikerinnen und Historiker unverzichtbar ist. Chronologisch geordnet werden sämtliche urkundlichen und historiographischen Quellen der römisch-deutschen Herrscher von den Karolingern bis zu Maximilian I. (751–1519) sowie der Päpste des frühen und hohen Mittelalters verzeichnet. Bei der Textsorte Regest handelt es sich um keine historisch-kritische Edition, sondern um eine Zusammenfassung des Inhalts der jeweiligen überlieferten Quelle. Sämtliche gedruckten Regestenbände wurden digitalisiert und ihre Inhalte zusätzlich in die Regestendatenbank übernommen. Diese bietet differenzierte Rechercheoptionen in den Volltexten und Vernetzungen beispielsweise mit der Regesta Imperii-Literaturdatenbank (RI-OPAC) als zentraler Bibliografie für die mediävistische Forschung. Sofern eine in den RI erfasste Urkunde innerhalb der MGH ediert wurde, findet sich eine entsprechende Verlinkung.
Eine weitere Verknüpfung der RI besteht mit dem Lichtbildarchiv älterer Originalurkunden Marburg (LBA), das seit 1928 die original überlieferten Urkunden des römisch-deutschen Reiches aus der Zeit vor 1250 sammelt und diese digitalisiert in einer Datenbank zugänglich macht. Die differenzierte Recherchemaske erlaubt beispielsweise die Suche nach Ausstellern, Empfängern, Mitsieglern, Datierungen oder den gegenwärtigen Aufbewahrungsorten von Urkunden. Sind diese innerhalb der RI ediert, gelangt man direkt in die Regesten und kann die Digitalisate unmittelbar vergleichen.
Neben Urkunden sind weitere Textquellen für die Geschichte des Mittelalters relevant. Das Repertorium Geschichtsquellen des deutschen Mittelalters ist ein bibliografisches und quellenkundliches Verzeichnis erzählender Geschichtsquellen wie Chroniken, Annalen oder Briefen aus der Zeit Karls des Großen bis zu Maximilian I. (ca. 750 – 1500). Es ist hervorgegangen aus dem traditionsreichen Repertorium Fontium Historiae Medii Aevi[180]. Neben der Beschreibung des Inhaltes der verzeichneten Quellen finden sich Nachweise der handschriftlichen Überlieferung, der relevanten Editionen, der Übersetzungen und Forschungsbeiträge.
Nicht unerwähnt bleiben soll schließlich eine für die Erforschung des Mittelalters wichtige Volltextdatenbank für epigraphische Zeugnisse, die Deutschen Inschriften Online (DIO). Auf Grundlage der gedruckten Edition Die deutschen Inschriften des Mittelalters und der Frühen Neuzeit[182] hat sie das Ziel, sämtliche lateinischen und deutschen Inschriften bis zum Jahr 1650 aus Deutschland, Österreich und Südtirol zu sammeln und zu edieren. Aufgenommen werden sowohl erhaltene Originalinschriften als auch kopial überlieferte Dokumente. Die Datenbank geht weit über die Digitalisierung der gedruckten Edition hinaus, indem sie weiteres Material integriert und differenzierte Recherchen sowohl in den Einzelbänden, als auch im Gesamtbestand und innerhalb der transkribierten Inschriften ermöglicht.
Bevor sich die Frühe Neuzeit als eigenständige Epoche innerhalb der Geschichtswissenschaft fest etabliert hat, war sie bereits prominenter Gegenstand bibliothekarischer Forschung und bibliografischer Dokumentation.
Insbesondere das als Zeitalter der Inkunabeln, der Wiegendrucke, bezeichnete erste halbe Jahrhundert des Buchdrucks zwischen 1450 und 1500 beschäftigte bereits in der Frühen Neuzeit Bibliothekare und Bibliophile. Im 19. Jahrhundert formierte sich auf Grundlage erster Inkunabelverzeichnisse die Inkunabelkunde als bibliothekswissenschaftliche Disziplin. Diese Verzeichnisse wurden immer vollständiger und immer weiter verbessert, so dass sie inzwischen – wie auch die Handschriftenkataloge – als (Volltext-)Datenbanken mit anderen Forschungsressourcen vernetzt werden können.
Der auf älteren Katalogen[183] aufbauende, an der Königlichen Bibliothek zu Berlin vor dem Ersten Weltkrieg begonnene und heute von der Staatsbibliothek zu Berlin – Preußischer Kulturbesitz fortgeführte Gesamtkatalog der Wiegendrucke (GW) verzeichnet alphabetisch sämtliche Drucke des 15. Jahrhunderts.[185] Da er bis heute nur zu Teilen vollendet ist, wird er parallel als Datenbank aufgebaut, um sämtliche in den gedruckten Bänden sowie im Manuskript nachgewiesenen Inkunabelausgaben in unterschiedlicher Erschließungstiefe zu verzeichnen. Über unterschiedliche Suchmasken und Register lassen sich differenziert Druckernamen, Druckorte, Autoren, Werke oder die GW-Nummern recherchieren.
Wie der deutsche GW verfolgt der von der British Library seit 1980 herausgegebene Incunabula Short Title Catalogue – the international database of 15th-century European printing (ISTC) das Ziel, einen Überblick über die weltweit erhaltenen Inkunabeln zu bieten.[187] Dieser internationale Kurztitelkatalog umfasst als Meta-Katalog die Kerndaten aus nationalen Inkunabelkatalogen mit dem Schwerpunkt auf Europa und Nordamerika. Mit 30.518 Ausgaben (Stand 2016) bietet der ISTC eine hervorragende Abdeckung. Verknüpfungen gibt es mit dem GW und mit vorhandenen Digitalisaten weltweit.
Für Forschungen zur konkreten Materialität von Inkunabeln sind zwei Datenbanken relevant, die mit GW, ISTC und weiteren Inkunabelverzeichnissen verknüpft sind: Material Evidence in Incunabula (MEI) und der von Paul Needham erstellte Index Possessorum Incunabulorum (IPI). In MEI werden sämtliche bekannten materialspezifischen Besonderheiten wie Buchschmuck, Einband, Stempel, Annotationen, Signaturen und Provenienzen erfasst. IPI basiert auf der Auswertung von etwa 200 publizierten Inkunabelkatalogen sowie Needhams eigenen Forschungen zu den früheren Besitzern von Inkunabeln. Insbesondere die Möglichkeit, nach vielfältigsten Provenienzen (zum Beispiel Personen, Institutionen, Monogramme) zu recherchieren, ist eine hervorragende Ergänzung zur Recherche in MEI.
Die größte Inkunabelsammlung des deutschen Sprach- und Kulturraums mit 20.337 Exemplaren von 9.782 Ausgaben besitzt die Bayerische Staatsbibliothek München. Nachgewiesen wird diese im Inkunabelkatalog BSB-Ink online, der auf der zwischen 1988 und 2021 erschienenen Printausgabe[192] beruht und Teil des Inkunabelkatalogs deutscher Bibliotheken (INKA) ist. Die genauen Exemplarbeschreibungen in INKA bieten ein hervorragendes Werkzeug für die Provenienzforschung und referenzieren die maßgeblichen Verzeichnisse und Bibliografien.
Für die Recherche nach Inkunabeln in deutschen und internationalen Sammlungen bieten die genannten Verzeichnisse, auf die vielfach auch der Volltextzugriff möglich ist, eine hervorragende Ausgangsbasis. Wie für Handschriften dürfte auch für die digitalisierten Inkunabeln in absehbarer Zeit eine Volltexterkennung möglich sein, so dass künftig nicht nur in den Inkunabelkatalogen mit sämtlichen Metadaten, sondern auch in den Volltexten der Inkunabeln selbst recherchiert werden kann.
Eine Normierung der Drucktypen und des Textlayouts begann erst im 16. Jahrhundert, in dem mediengeschichtlich die Epoche der Alten Drucke ihren Anfang nahm. Aus der Katalogisierung der deutschen und auf deutschem Territorium erschienenen Drucke des 16., 17. und 18. Jahrhunderts entwickelte sich die retrospektive Nationalbibliografie, die im Rahmen der Arbeitsgemeinschaft Sammlung Deutscher Drucke (AG SDD) zur Verteilten deutschen Nationalbibliothek wurde (vgl. Kap. 1.2). Im Unterschied zu dem zunächst als Druckausgabe erschienenen, erst später in eine Datenbank überführten VD16 wurden VD17 und VD18 von Beginn an als Datenbanken konzipiert. Da zeitgleich um die Jahrtausendwende mit den Digitalisierungszentren in München und Göttingen die Digitalisierung des schriftlichen Kulturerbes begann, konnten mit der autoptischen Katalogisierung der Texte zunächst ausgewählte Schlüsselseiten, später die Werke vollständig digitalisiert werden. Auf Grundlage der retrospektiven deutschen Nationalbibliografie für das 16.–18. Jahrhundert begann die virtuelle digitale deutsche Nationalbibliothek Gestalt anzunehmen. Ihre Volltexttransformation durch Einsatz von OCR-Technologien wird in Zukunft eine Volltextsuche über das gesamte schriftliche Kulturerbe der Frühen Neuzeit ermöglichen.
Da sich die VDs auf die deutschsprachigen oder auf deutschem Territorium gedruckten Werke konzentrieren, ist für die Recherche historischer Drucke auch anderer Sprachen und Herkunft ein weiteres Portal relevant. Das Zentrale Verzeichnis Digitalisierter Drucke (zvdd) ist das Nachweisportal für die in Deutschland erstellten Digitalisate von Druckwerken vom 15. Jahrhundert bis heute – insofern sind auch das 19. und 20. Jahrhundert inkludiert, auch wenn für diesen Bereich angesichts der großen Menge der Drucke sowie ihrer Katalogsituation Vollständigkeit nur schwer zu erzielen ist (vgl. Kap. 1.2). Über eine einheitliche Recherchemaske lässt sich nach Titeln, Autoren, Druckern, Druckorten oder Erscheinungszeiträumen suchen.
Für den deutschsprachigen Raum ist ferner e-rara als Plattform für digitalisierte Drucke aus Schweizer Bibliotheken zu nennen. Nachgewiesen werden Bücher, Karten und illustrierte Materialien von den Anfängen des Buchdrucks bis ins 20. Jahrhundert.
Auch die englische Buchproduktion der Frühen Neuzeit ist in unterschiedlichen Volltextdatenbanken inzwischen ausgezeichnet dokumentiert. Early English Books Online (EEBO) umfasst Bücher aus der Zeit vom Beginn der englischen Buchproduktion bis zu Shakespeare und ist vergleichbar mit VD16 und VD17. Sämtliche Werke sind im Volltext durchsuchbar und können heruntergeladen oder ausgedruckt werden.
Die frühneuzeitliche englische Textproduktion des 18. Jahrhunderts wird außerdem durch die Eighteenth Century Collections Online (ECCO) repräsentiert.[201] Enthalten sind zwischen 1701 und 1800 vorwiegend in England erschienene Bücher, Pamphlete, Essays und Einblattdrucke sämtlicher Fachgebiete. Insbesondere für vergleichende Forschungen zwischen dem deutschen und englischen Kulturraum, beispielsweise zu Fragen der Verbreitung von Autoren, Texten und damit Wissen in der Frühen Neuzeit, bieten EEBO und ECCO einen reichen Schatz an Quellen, dessen systematische Erforschung durch die Verbindung von close reading und distant reading und den Einsatz der Möglichkeiten der Digital Humanities erst am Anfang steht.
Zentrale Gegenstände der Frühneuzeitforschung betreffen die religiösen und sozialen Diskurse im Spannungsfeld von Reformation, Gegenreformation und Dreißigjährigem Krieg. Für den Protestantismus bietet die Digital Library of Classic Protestant Texts (DLCP) Volltexte von etwa 1.500 Werken von mehr als 325 protestantischen Autoren des 16. und 17. Jahrhunderts wie Martin Luther, Johannes Calvin oder Ulrich Zwingli. Neben theologischen Schriften beinhaltet DLCP auch Beichtschriften, Bibelkommentare, Streitschriften, Katechismen und liturgischen Schriften.
Das Pendant für den Katholizismus ist die Digital Library of the Catholic Reformation (DLCR) mit etwa 2.000 Texten katholischer Autoren desselben Zeitraumes. Theologische Schriften sind genauso inkludiert wie Papsturkunden, Synodalbeschlüsse, Katechismen, Beichthandbücher, Bibelkommentare, religiöse Dramen, liturgische Schriften, Inquisitionshandbücher oder Andachtsbücher. In beiden Fällen handelt es sich um kombinierte Volltext- und Faksimiledatenbanken, deren Suchmasken differenzierte Recherchen innerhalb der Volltexte ermöglichen.
In der Frühen Neuzeit gewannen nach der Entdeckung des amerikanischen Kontinents die USA eine immer wichtigere Bedeutung innerhalb der transatlantischen Geschichte. Eine ausgezeichnete Quellengrundlage bietet die Volltextdatenbank Early American Imprints 1639–1819. Innerhalb der Series I: Evans, 1639–1800 (EAI I), die auf der Bibliografie von Charles Evans[206] beruht, finden sich mehr als 36.000 digitale Ausgaben der zwischen 1639 und 1800 in Nordamerika publizierten Bücher.[207] Die Series II: Shaw-Shoemaker, 1801–1819 (EAI II), basierend auf der Bibliografie von Ralph R. Shaw und Richard H. Shoemaker[209], schließt daran an und umfasst 37.000 digitalisierte Werke, die zwischen 1801 und 1819 in Nordamerika erschienen sind.
Wie diese Beispiele zeigen, ist die Epoche der Frühen Neuzeit ein „goldenes Zeitalter für die Retrodigitalisierung“[210]: Die durch Gutenberg eingeläutete Medienrevolution steigerte die Produktion von Schriftlichkeit in zuvor nicht gekanntem Umfang. Insofern bietet sich der Frühneuzeitforschung ein im Vergleich zu vorausgehenden Epochen außerordentlich vielfältiges Portfolio an schriftlichen Quellen. Der in der Regel gute konservatorische Zustand der Bücher dieser Jahrhunderte durch die Verwendung von Hadernpapier sowie die längst erloschenen Urheberrechte geben den Gedächtnisinstitutionen große Freiheiten in ihrer Digitalisierungsentscheidung. Die Volltextdatenbanken, in die die digitalisierten Sammlungen aufgenommen werden, werden zum wichtigsten Instrument frühneuzeitlicher Quellenkunde.
Angesichts der seit dem 19. Jahrhundert weiter expandierenden Schriftlichkeit durch technologische Innovationen der Buchherstellung, neue Textsorten und neue soziale Gruppen von Leserinnen und Lesern stehen der Erforschung der jüngsten Epochen der Geschichte immer neue und immer mehr Quellen zur Verfügung. Begünstigend wirkt, dass OCR-Erkennung moderner Typographien weniger aufwändig ist als im Falle von Inkunabeln, frühen Drucken oder handschriftlichen Dokumenten älterer Epochen.
Ein ähnliches Konzept wie ECCO für englische Quellen des 18. Jahrhunderts verfolgt für das 19. Jahrhundert die Volltextdatenbank Nineteenth Century Collections Online (NCCO). Im Unterschied zu ECCO umfasst sie jedoch ausgewählte internationale Sammlungen aus den Bereichen Geschichte, Politik, Literatur und darstellende Kunst. Im Einzelnen: Asia and the West: Diplomacy and Cultural Exchange, British Politics and Society, British Theatre, Music and the Arts: High and Popular Culture, Europe and Africa: Commerce, Christianity, Civilization, and Conquest, European Literature, 1790–1840: The Corvey Collection[212], Photography: The World Through the Lens und Science, Technology and Medicine, 1780–1925. Die Quellen sind in ihren Metadaten sowie im Volltext differenziert durchsuchbar, ermöglichen einen Download und die Weiterbearbeitung.
Eine wichtige Quellengattung für das 19. und 20. Jahrhundert (und partiell auch für die Frühe Neuzeit), die digitalisiert und in Volltextdatenbanken zur Verfügung steht, sind Zeitungen, für die hier nur einige herausragende Beispiele genannt werden. Eine umfassende Übersicht dazu gibt der Clio-Guide Zeitungen. Grundsätzlich ist zu beachten, dass historische Zeitungen aus der Zeit vor 1945 in der Regel ohne urheberrechtliche Schranken digitalisiert und im Open Access zugänglich gemacht werden können, während für Zeitungen aus der zweiten Hälfte des 20. Jahrhunderts Urheberrechte bestehen. Daher hängt die Nutzungsmöglichkeit von Lizenzen ab – sei es durch die lokale Bibliothek, durch den FID oder als Nationallizenz. Einen jeweils aktuellen Überblick bieten DBIS sowie die jeweiligen Lizenzinformationen der zuständigen FIDs.[214]
Eine breite Titelvielfalt seit dem 16. Jahrhundert bietet der digitale Zeitungs- und Zeitschriftenlesesaal der Österreichischen Nationalbibliothek mit ANNO – Austrian Newspapers Online. Das Portal digiPress präsentiert den historischen Zeitungsbestand der Bayerischen Staatsbibliothek vom 17. Jahrhundert bis ins frühe 20. Jahrhundert mit regionalem Schwerpunkt in Süddeutschland. Der Zugriff auf die Quellen ist über die Titelliste, den Kalender sowie die Volltextsuche möglich. ZEFYS - Zeitungsinformationssystem der Staatsbibliothek zu Berlin besitzt einen regionalen Schwerpunkt im Norden und Nordosten des deutschen Sprachraumes: Die Amtspresse Preußens beispielsweise umfasst zentrale preußische Tageszeitungen der Zeit zwischen 1856 und 1944, das DDR-Presseportal die politisch maßgeblichen Zeitungen der Deutschen Demokratischen Republik der Jahre zwischen 1945 und 1994. Im Hinblick auf eine regionale Abdeckung Deutschlands ist schließlich das Zeitungsportal Nordrhein-Westfalen, zeit.punktNRW, zu nennen, das regionale Zeitungen aus den Bibliotheken und Archiven des Landes mit Volltextsuche digital bereitstellt.
Der Nachweis der Digitalisierungsprojekte zu historischen Zeitungen in Deutschland erfolgt künftig durch das Deutsche Zeitungsportal als Teil der Deutschen Digitalen Bibliothek (DDB).[220] Es wird von mehreren großen Bibliotheken getragen und bietet historische Zeitungen des 17. bis 20 Jahrhunderts mit der Möglichkeit einer Volltextsuche an.
Für Großbritannien sind zwei Volltextdatenbanken für Zeitungen exemplarisch zu nennen: 19th Century British Library Newspapers mit mehr als 160 lokalen und regionalen Zeitungen aus dem Bestand der British Library aus der Zeit von 1732–1950 sowie die Burney collection mit insgesamt 1.270 englischen Zeitungen und Flugschriften des 17. und 18. Jahrhunderts aus der Sammlung des Charles Burney (1757–1817). Mit enthalten sind Parlamentsveröffentlichungen, tagesaktuelle Nachrichten aus London, dem Britischen Empire, den Nachbarländern und deren Königshäusern oder Regierungen.
Für Frankreich steht beispielsweise die einflussreiche Tageszeitung Le Monde als Volltextdatenbank für die Jahre 1944–2000 als FID-Lizenz zur Verfügung.
Vor dem Hintergrund dieser ausgewählten Volltextdatenbanken für Zeitungen einzelner Länder Europas entsteht mit Europeana Newspapers ein gemeinsames Angebot, in dem europäische Zeitungen als historische Quellen künftig vergleichend erforscht werden können.
Erweitert man den Blick von Europa auf die Vereinigten Staaten von Amerika, so stehen auch hier zahlreiche Volltextdatenbanken für Zeitungen zur Verfügung. America‘s Historical Newspapers ist eine umfassende Volltextdatenbank für digitalisierte Zeitungen der USA aus der Zeit zwischen 1690 und 1922. Sie beinhaltet neben überregional bedeutenden Titeln auch Zeitungen aus 50 Bundesstaaten sowie interessante deutsch-amerikanische Periodika. Die Volltextsuche ermöglicht die Analyse politischer und gesellschaftlicher Diskurse auf dem nordamerikanischen Kontinent in einer diachronen Perspektive.
Die großen US-amerikanischen Tageszeitungen, New York Times für die Jahre 1851–2020 und Washington Post für die Jahre 1877–2007 stehen als FID-Lizenzen zur Verfügung. Die Volltextsuche ermöglicht die Recherche innerhalb der einzeln indexierten Artikel, Kommentare, Rezensionen, Fotos, Karikaturen, Werbeanzeigen, Leserbriefe und Familienanzeigen.
Auch das Regierungshandeln des US-Kongresses ist in digitalisierten Quellen ausgezeichnet dokumentiert. Die Volltextdatenbank U.S. Congressional Serial Set 1817–1980/1994 enthält etwa 350.000 Publikationen aus Gremien und Arbeitsgruppen des US-Kongresses sowie von Regierungsbehörden. Teil der Datenbank sind die American State Papers 1789–1838, die Dokumente aus der Periode der ersten 14 US-Kongresse vor 1817 beinhalten. Die Datenbank bietet eine Fülle an Materialien zu allen Bereichen der Geschichte, Politik, Wirtschaft und Kultur der Vereinigten Staaten, aber vielfach auch darüber hinaus, sofern die Beziehungen zu anderen Ländern betroffen sind.
Trotz vielfältiger Schwierigkeiten und Restriktionen bei der Erschließung und Digitalisierung der in osteuropäischen Bibliotheken und Archiven aufbewahrten Quellen existieren inzwischen Volltextdatenbanken zur Geschichte Osteuropas. Integrum World Wide ist die umfangreichste Volltextdatenbank Russlands und der GUS mit etwa 360 Millionen Quellendokumenten aus den Bereichen Politik, Kultur, Wirtschaft und Gesellschaft. Enthalten sind beispielsweise Texte aus der russischen und englischen Presse (regionale und überregionale Periodika, Monitor-Dienste von Fernsehen und Radio, Presseagenturen), Statistiken (Goskomstat), Gesetzestexte, Regierungsveröffentlichungen, Patentschriften (Rospatent), bibliografische Datenbanken der Russischen Akademie der Wissenschaften (INION) oder Internetquellen.
Eine besondere Art Volltextdatenbank stellt das vom Deutschen Historischen Museum (DHM) und Haus der Geschichte (HdG) betriebene Lebendige Museum online (LeMO) dar: Hier werden (Volltext-) Datenbanken musealer Objekte mit Texten, Karten, Statistiken, Bildern sowie Film- und Tondokumenten in einem attraktiven Portal präsentiert.
Das Georg-Eckert-Institut – Leibniz-Institut für Bildungsmedien (GEI), das auch für seine Forschungsaktivitäten im Bereich Volltexterkennnung bekannt ist, bietet in seiner Volltextdatenbank GEI-Digital – Die digitale Schulbuchbibliothek eine Volltextdatenbank für digitalisierte historische Schulbücher, die als Quellen für bildungswissenschaftliche Fragen dienen können.
Welche konkreten Nutzungsszenarien bieten historische Volltext-datenbanken für Historikerinnen und Historiker? Statt zeitinten-siver Bibliotheks- und Archivreisen zu den Originalquellen, statt aufwändiger Suche nach relevanten Textstellen in Quelleneditionen oder Forschungsliteratur ermöglichen Volltextdatenbanken eine zielgenaue Identifizierung relevanter Quellen und Forschungsliteratur sowie den unmittelbaren Zugriff hierauf. Auf Grundlage digitaler Bibliotheken und vernetzter Volltextdatenbanken lassen sich quantitative Analysen historischer Kulturen und Gesellschaften in einem zuvor unbekannten Umfang vornehmen. Beispielsweise ist denkbar, durch automatische Analyse großer Textcorpora von Primärquellen größerer Zeiträume Thesauri historischer Begriffe zu generieren und ihre Semantik differenzierter und umfassender zu analysieren, als es beispielsweise in den Geschichtlichen Grundbegriffen in vordigitaler Zeit möglich war.[234] Künftig wird nicht nur das schriftliche Kulturerbe in einem System vernetzter historischer Volltextdatenbanken zur Verfügung stehen. Es wird möglich sein, Forschungsfragen in einer Qualität und Quantität zu bearbeiten, die in analoger Zeit kaum in einer einzigen Forschergeneration hätten bearbeitet werden können.
Die digitale Transformation verwandelt die traditionelle „Bibliothek der Bücher“ in eine „Bibliothek der Texte“[235], die als Volltexte beliebig kontextualisiert werden können. Text, Mensch und Welt verschmelzen in einem prinzipiell grenzenlosen Hypertext. Texte benötigen keine Bücher mehr – sie haben sich von Büchern und Bibliotheken emanzipiert.[236]
Der Bibliothekskatalog der Zukunft wird nicht mehr nur bibliografische Metadaten von Forschungsliteratur und Standorte gedruckter Bücher nachweisen, sondern als Suchmaschine eine kombinierte Recherche in Metadaten und Volltexten im Textraum sämtlicher digital(isiert)en Bücher und Forschungsressourcen der jeweiligen Bibliothek ermöglichen und den direkten Zugriff auf die Quellen und Volltexte bieten. Doch nicht genug: Lokale Texträume verschmelzen mit globalen Textwelten, in denen geschichtswissenschaftliche Quellen und Forschungsliteratur eine disziplinäre Textsphäre bilden, die verwoben ist mit Textsphären anderer Disziplinen: Interdisziplinäre Volltextrecherchen im universellen Text- und Datenraum global vernetzter digitaler Bibliotheken werden möglich. Bibliotheken haben aber auch in Zukunft die Aufgabe, Bücher, Texte, Informationen, Daten und Wissen für den lesenden Menschen zu strukturieren.
Die digitale Transformation verwandelt die traditionelle „Bibliothek der Bücher“ aber nicht allein in eine „Bibliothek der Texte“, sondern zugleich in eine „Bibliothek der Informationen“ und in eine „Bibliothek der Daten“. Nachdem angesichts der wachsenden Bedeutung von Forschungsdaten innerhalb digital arbeitender Wissenschaften der Rat für Informationsinfrastrukturen (RfII) die Gründung der Nationalen Forschungsdateninfrastruktur (NFDI) angestoßen hat, befinden sich mehrere geisteswissenschaftliche Konsortien im Aufbau.[239] Vertreten durch den Verband der Historiker und Historikerinnen Deutschlands (VHD) sind die Geschichtswissenschaften Teil des NFDI4Memory-Konsortiums, das Forschungseinrichtungen, Gedächtnisinstitutionen und Informationsinfrastrukturen aus den historisch arbeitenden Geisteswissenschaften vereint.[241]
Historische Forschungsdaten („historical research data“) werden sehr breit verstanden: „Under the broad label of ‚data‘ one finds texts (handwritten or printed), images, objects, statistical databases, maps, and films, among others, each with their own specificities and challenges. Different types of data and different research methods require modular and flexible solutions that currently only exist in limited contexts.“[242] Kernziele von NFDI4Memory sind: „Linking Research, Memory Institutions and Infrastructures“, „Integrating Historical Source Criticism into Data Services“, „Network of Historically Oriented Research Communities“, „Knowledge Order for the Digital Future of the Past“, „Advancing the Analog / Digital Interface of Historical Source Material and Data“, „Generating Standards for Historical Research Data and Sustainability“, „Education and Citizen Participation“.[243] Ein zentrales Anliegen von NFDI4Memory ist es, die spezifische Tradition der Quellenkritik für das digitale Zeitalter im Sinne einer digitalen Quellenkritik weiterzuentwickeln. Auf diese Weise können aus geschichtswissenschaftlicher Perspektive im Zeitalter der Digital Humanities die „Bibliothek der Bücher“, die „Bibliothek der Texte“ und die „Bibliothek der Daten“ durchaus zusammengedacht werden.[244]
Neben NFDI4Memory sind für geschichtswissenschaftliches Arbeiten weitere NFDI-Konsortien relevant: Text+ als Konsortium für Sprach- und textbasierte Forschungsdateninfrastruktur, NFDI4Culture als Konsortium für Forschungsdaten zu materiellen und immateriellen Kulturgütern und NFDI4Objects – Forschungsdateninfrastruktur für die materiellen Hinterlassenschaften der Menschheitsgeschichte. Vergleichbar mit den früheren SSGs oder FIDs der Bibliotheken entstehen innerhalb der NFDI Informationsinfrastrukturen für Forschungsdaten, bei denen nicht nur Bibliotheken, sondern zahlreiche weitere Partner eng zusammenwirken.
Volltextdatenbanken zählen zu den wichtigsten Instrumenten historischen Arbeitens, sei es für Quellen, Quelleneditionen oder Forschungsliteratur. Die technisch realisierte Volltexterkennung wird zum „Qualitätskriterium von digitalen Sammlungen“[248]. Da geschichtswissenschaftliches Arbeiten in der Regel mit einer Recherche nach Fachliteratur zu einem Thema in einer bibliografischen Datenbank beginnt, bieten historische Volltextdatenbanken die komfortable Möglichkeit, aus dieser Recherche heraus über Linkresolver direkt zum Volltext innerhalb einer Volltextdatenbank zu gelangen. Immer häufiger entwickeln sich bibliografische Datenbanken auch selbst zu Volltextdatenbanken, so dass die bibliografische Recherche unmittelbar zum Volltext der Forschungsliteratur führt. Geschichtswissenschaftliches Arbeiten bedeutet aber auch die intensive Arbeit mit Quellen. Wie Forschungsliteratur werden diese ebenfalls nicht nur als digitale Faksimiles reproduziert, sondern durch Anwendung der HTR/OCR-Technologien in Volltextdatenbanken aufbereitet.
Das Ziel, das gesamte handschriftliche und gedruckte Kulturerbe aus Antike, Mittelalter und Neuzeit digital zu faksimilieren und im Volltext zu erkennen, liegt für den deutschen Sprachraum inzwischen in greifbarer Nähe. Die für die Geschichtswissenschaft zentralen Schriftquellen werden sich künftig als fortlaufender und vernetzter Text vor den Augen der Lesenden entfalten. Es wird möglich sein, nicht nur innerhalb der Kontinente digital verfügbarer Forschungsliteratur und Forschungsdaten, sondern zugleich innerhalb des digitalisierten schriftlichen Kulturerbes zu „googeln“.
In beiden Fällen – Volltextdatenbanken für Forschungsliteratur und Volltextdatenbanken für Quellen – ermöglicht eine Volltextsuche die Formulierung von Fragen und die Gewinnung von Erkenntnissen, für die eine automatisierte Analyse großer Textmengen durch corpusbasierte Forschungsfragen grundlegende Voraussetzung ist. Volltextdatenbanken sind somit weit mehr als nur eine neue Form der Publikation und Archivierung zuvor gedruckten oder genuin digital repräsentierten Wissens, indem sie differenzierte Instrumente der Erschließung und Analyse von Texten bereitstellen und neue Fragestellungen und Antworten ermöglichen. Auch in den nächsten Jahren ist mit einer kontinuierlichen Zunahme von Volltextdatenbanken zu rechnen, da nicht nur immer größere Textmengen erstmals digitalisiert sind, sondern auch viele der bisher lediglich in Image-Digitalisaten vorliegenden Sammlungen mit automatischen Texterkennungsverfahren aufbereitet werden.
Vor dem Hintergrund der skizzierten Entstehung und Charakterisierung historischer Volltextdatenbanken lassen sich bereits jetzt Szenarien der Zukunft erkennen, in denen historische Volltextdatenbanken ihre Potenziale vollends entfalten können. Insbesondere ist zu erwarten, dass die beiden Säulen geschichtswissenschaftlichen Arbeitens mit Texten – das Studium der Quellen und der Forschungsliteratur – durch immer umfassendere Volltextdatenbanken ganz neue Qualitäten ermöglichen. Zugleich werden diese Textwelten immer differenzierter miteinander verwoben – Quellen mit Quellen, Quellen mit Forschungsliteratur und Forschungsliteratur mit Forschungsliteratur. In Bezug auf den Umgang mit historischen Quellen tritt neben die Kompetenzen in traditionellen historischen Grundwissenschaften wie Paläographie oder Kodikologie die digitale Quellenkritik. Insbesondere für Forschungsprojekte im Kontext historischer Volltextdatenbanken spielen die Fächer Informatik, Informationswissenschaft und Bibliothekswissenschaft eine gleichermaßen zentrale Rolle.
Künftig werden sich nicht nur menschliche Historikerinnen und Historiker in diese Textwelten von Quellen und Forschungsliteratur begeben, um in individueller oder kollaborativer Forschung zu neuen Erkenntnissen zu gelangen. Je mehr Texte digitalisiert, volltexterkannt und prozessierbar für weitere Bearbeitung gemacht werden, je mehr Texte als genuine Open-Access-Publikationen vorliegen, desto größere Potenziale gewinnen nicht nur Algorithmus-basierte Analyseverfahren wie Text Mining, sondern auch KI-Technologien wie Large Language Models (LLMs).[249]
Bereits jetzt ist überdeutlich, dass sich (geschichts-)wissenschaftliches Arbeiten in Zukunft fundamental ändern wird. Historikerinnen und Historiker werden weiterhin forschungsrelevante Fragen auf der Basis intensiver Lektüre von Quellen und Forschungsliteratur bearbeiten. Historische Kompetenz wird zunehmend jedoch auch darin bestehen, KI-basierte oder durch den Einsatz von KI ergänzte Analysen zu prüfen und fachlich zu bewerten. Beschleunigtes distant reading, durch das Quellen und Forschungsliteratur schneller aufgefunden oder analysiert werden können, ermöglicht mehr Zeit für interpretatorische Arbeit im close reading. Geschichtswissenschaftliches Arbeiten basiert künftig nicht nur auf einer fundierten Fachkompetenz, die sich durch Anwendung klassischer hermeneutischer Verfahren auszeichnet, sondern gleichermaßen auf einer fundierten Informations-, Medien-und Datenkompetenz, die einer stetig wachsenden Menge verfügbarer wissenschaftlicher Informationen souverän begegnet, und schließlich auf einer fundierten Datenkompetenz, die mit unterschiedlichsten historischen Daten umzugehen weiß. Hierzu gehören beispielsweise Metadaten von Digitalisaten historischer Quellen oder TEI/XML-Code, mit dem Texte ausgezeichnet werden, um beispielsweise digitale Editionen zu erstellen.
Innerhalb des Prozesses, den die traditionelle, analoge Geschichtswissenschaft über die Digitalisierung hin zur digitalen Transformation durchläuft, nehmen historische Volltextdatenbanken eine Schlüsselrolle ein: An ihnen werden zahlreiche Aspekte dieses Wandels exemplarisch deutlich. Selbstverständlich untersuchen auch heute noch Historikerinnen und Historiker originale historische Quellen. Sofern von diesen analogen Originalquellen jedoch digitale Repräsentationen wie digitale Faksimiles oder Transkriptionen hergestellt werden, ist auch mit diesen im Forschungsprozess umzugehen. Ein weiterer Quellentypus, der für die Zeitgeschichte immer wichtiger wird, sind Quellen, die „digital born“ sind, wie beispielsweise elektronische Akten oder Postings in Sozialen Netzwerken. Da sich digitale Quellen beliebig kopieren lassen, stellt sich nicht nur die Frage nach möglichen Unterscheidungskriterien zwischen Original und Kopie im Digitalen, sondern auch die grundsätzliche Frage nach einer zeitgemäßen Quellenkritik. Eine solche „digitale Quellenkritik“ sollte eingebettet sein in eine „digitale Hermeneutik“, wie sie Andreas Fickers vorschlägt: „Es ist höchste Zeit, die digitale Hermeneutik zu entwickeln und sie zum Standard für die Ausbildung zukünftiger Historiker zu machen […] Die Sprachen des Historikers waren lange Zeit tote Sprachen wie Latein oder Altgriechisch. Der Geschichtswissenschaftler der Zukunft muss neben diesen auch Programmiersprachen verstehen.“[250]
Geschichtswissenschaftliche Informations- und Medienkompetenz, Datenkompetenz sowie digitale Quellenkritik sind künftig die Säulen, auf denen die Grundsätze guter wissenschaftlicher Praxis ruhen – gerade auch im Hinblick auf die Einbindung von Methoden künstlicher Intelligenz. Geschichtswissenschaftliches Arbeiten in der digitalen Welt bietet eine Vielzahl von Perspektiven und Potenzialen, die in Gestalt historischer Volltextdatenbanken in nuce erkennbar sind.
Adams, Thomas R.; Barker, Nicolas, A New Model for the Study of the Book, in: A Potencie of Life. Books in Society. The Clark Lectures 1986–1987, Hrsg. von Nicolas Barker, London 1993, S. 5–43.
Blickle, Peter, Die Revolution von 1525, 4., durchgesehene und bibliografisch erweiterte Auflage, München 2004.
Bösch, Frank; Schlotheuber, Eva, Quellenkritik im digitalen Zeitalter: Die Historischen Grundwissenschaften als zentrale Kompetenz der Geschichtswissenschaft und benachbarter Fächer, in: Historische Grundwissenschaften und die digitale Herausforderung, Hrsg. für H-Soz-Kult von Rüdiger Hohls, Claudia Prinz und Eva Schlotheuber, Historisches Forum 18 (2016), S. 16–20,
https://edoc.hu-berlin.de/handle/18452/19491.
Darnton, Robert, What is the History of Books?, in: Daedalus 111 (1982), S. 65–83.
Darnton, Robert, What is the History of Books?, in: Modern Intellectual History 4 (2007), S. 495–508.
Deck, Klaus-Georg, Digital Humanities – Eine Herausforderung an die Informatik und an die Geisteswissenschaften, in: Wie Digitalität die Geisteswissenschaften verändert: Neue Forschungsgegenstände und Methoden, hrsg. von Martin Huber und Sybille Krämer, 2018 (= Sonderband der Zeitschrift für digitale Geisteswissenschaften, 3),
https://doi.org/10.17175/sb003_002.
Digital Humanities in den Geschichtswissenschaften, hrsg. von Christina Antenhofer, Christoph Kühberger und Arno Strohmeyer, Wien 2024.
Enderle, Wilfried, Frühe Neuzeit, in: Clio Guide – Ein Handbuch zu digitalen Ressourcen für die Geschichtswissenschaften, hrsg. von Silvia Daniel, Wilfried Enderle, Rüdiger Hohls, Thomas Meyer, Jens Prellwitz, Claudia Prinz, Annette Schuhmann, Silke Schwandt, 3. erw. und aktualisierte Aufl., Berlin 2023,
https://doi.org/10.60693/yqjz-7f44.
Eisermann, Falk, The Gutenberg Galaxy’s Dark Matter: Lost Incunabula, and Ways to Retrieve Them, in: Flavia Bruni und Andrew Pettegree (Hrg.), Lost Books. Reconstructing the Print World of Pre-Industrial Europe. Leiden/Boston: Brill 2016, S. 31–54.
Engl, Elisabeth, OCR-D kompakt. Ergebnisse und Stand der Forschung in der Förderinitiative, in: Bibliothek – Forschung und Praxis 44 (2020), 2, S. 218–230,
https://doi.org/10.1515/bfp-2020-0024.
Ernst, Michael, Rechtliche Rahmenbedingungen der Digitalisierung kulturellen Erbes. Legal framework for digitising cultural heritage, in: Bibliotheksdienst 52 (2018) 9, S. 687–697;
http://doi.org/10.1515/bd-2018-0082.
Euler, Ellen, Open Access, Open Data und Open Science als wesentliche Pfeiler einer (nachhaltig) erfolgreichen digitalen Transformation der Kulturerbeeinrichtungen und des Kulturbetriebes, 2018,
https://doi.org/10.11588/artdok.00006135.
Fabian, Bernhard, Buch, Bibliothek und geisteswissenschaftliche Forschung. Zu Problemen der Literaturversorgung und Literaturproduktion in der Bundesrepublik Deutschland, Göttingen 1983.
Gasser, Sonja, Das Digitalisat als Objekt der Begierde. Anforderungen an digitale Sammlungen für Forschung in der Digitalen Kunstgeschichte, in: Objekte im Netz. Wissenschaftliche Sammlungen im digitalen Wandel, Hrsg. von Udo Andraschke, Sarah Wagner, Bielefeld 2020, S. 261–276, https://doi.org/10.1515/9783839455715-009.
Haber, Peter, Digital Past. Geschichtswissenschaft im digitalen Zeitalter, München 2011.
Hertling, Anke; Klaes, Sebastian, Volltexte für die Forschung: OCR partizipativ, iterativ und on Demand, in: O-Bib. Das offene Bibliotheksjournal 9 (2022) 3, S.1–11,
https://doi.org/10.5282/o-bib/5832.
Huff, Dorothee; Stöbener, Kristina, Projekt OCR-BW: Automatische Texterkennung von Handschriften, in: O-Bib. Das Offene Bibliotheksjournal 9 (2022) 4, S. 1–19,
https://doi.org/10.5282/o-bib/5885.
Johrendt, Jochen, Digitalisierung als Chance, in: Historische Grundwissenschaften und die digitale Herausforderung, Hrsg. für H-Soz-Kult von Rüdiger Hohls, Claudia Prinz und Eva Schlotheuber, Historisches Forum 18 (2016), S. 41–42,
https://edoc.hu-berlin.de/handle/18452/19491.
Kann, Bettina, Hintersonnleitner, Michael, Volltextsuche in historischen Texten – Erfahrungen aus den Projekten der Österreichischen Nationalbibliothek, in: Bibliothek – Forschung und Praxis 39 (2015) 1, S. 73–79,
http://doi.org/10.1515/bfp-2015-0004.
Kobel, Esther; Volp, Ulrich, Distant reading – Perspektiven einer digitalen Zeit. Eine Einführung, in: Journal of Ethics in Antiquity and Christianity 4 (2022), S. 5–10.
Lauer, Gerhard, Was ist Buchwissenschaft, wenn sie eine Disziplin ist?, in: Archiv für Geschichte des Buchwesens 77 (2022), S. 173–178.
McLuhan, Marshall, Die Gutenberg-Galaxis. Das Ende des Buchzeitalters, München 1968.
McLuhan, Marshall; Powers, Bruce R., The global village: der Weg der Mediengesellschaft in das 21. Jahrhundert, Paderborn 1995.
Mühlberger, Günter, Digitalisierung historischer Zeitungen aus dem Blickwinkel der automatisierten Text- und Strukturerkennung (OCR), in: Zeitschrift für Bibliothekswesen und Bibliographie 58 (2011), 1, S. 10–18,
http://doi.org/10.3196/186429501158135.
Otlet, Paul, Traité de documentation. Le livre sur le livre. Théorie et pratique, Brüssel 1934.
Rautenberg, Ursula (Hrsg.), Buchwissenschaft in Deutschland. Ein Handbuch, Berlin - Boston 2010.
Rehbein, Malte, Digitalisierung braucht Historiker/innen, die sie beherrschen, nicht beherrscht, in: Historische Grundwissenschaften und die digitale Herausforderung, Hrsg. für H-Soz-Kult von Rüdiger Hohls, Claudia Prinz und Eva Schlotheuber, Historisches Forum 18 (2016), S. 45–52,
https://edoc.hu-berlin.de/handle/18452/19491.
Sahle, Patrick, Digitale Editionsformen: zum Umgang mit der Überlieferung unter den Bedingungen des Medienwandels, 3 Bände, Norderstedt 2013.
Sahle, Patrick, Digitale Edition, in: Jannidis, Fotis; Kohle, Hubertus; Rehbein Malte (Hrsg.): Digital Humanities: Eine Einführung, Stuttgart 2017, S. 234–249.
Schmitz, Wolfgang, Grundriss der Inkunabelkunde. Das gedruckte Buch im Zeitalter des Medienwechsels, Stuttgart 2023.
Stäcker, Thomas, Konversion des kulturellen Erbes für die Forschung: Volltextbeschaffung und -bereitstellung als Aufgabe der Bibliotheken, in: O-Bib 1 (2014), S. 220–237.
http://doi.org/10.5282/o-bib/2014H1S220-237.
Steinhauer, Eric W., Die Bibliothek 2040 – eine Einrichtung der digitalen Transformation mit vielen Büchern?, in: Bibliothek: Forschung und Praxis 47 (2023) 1, S. 29–32, ,
https://doi.org/10.1515/bfp-2023-0014.
Zotter, Hans, Erlebnisräume, gebaut aus Erinnerungen. Die Sondersammlung als Teaching Library, in: Sondersammlungen im 21. Jahrhundert: Organisation, Dienstleistungen, Ressourcen, Hrsg. von Graham Jefcoate, Jürgen Weber, Wiesbaden 2008, S. 136–144.
Abbildung 4. Verteilte deutsche Nationalbibliothek und retrospektive deutsche Nationalbibliografie
Die Idee einer Verteilten nationalen Forschungsbibliothek[51] entstand nach dem Zweiten Weltkrieg, als Studium, Forschung und Lehre an den Universitäten vor dem Hintergrund begrenzter Ressourcen effizient wieder aufgenommen werden sollten. Bereits damals war es keiner einzelnen deutschen Bibliothek möglich, die national und international publizierte Forschungsliteratur auch nur annähernd umfassend zu erwerben. Daher wurde 1949 das kooperativ organisierte Modell unterschiedlicher Sondersammelgebiete (SSGs) etabliert, durch das führende wissenschaftliche Bibliotheken mit Unterstützung der DFG sicherstellten, dass die relevanteste internationale Forschungsliteratur in Deutschland in mindestens einem gedruckten Exemplar zur Verfügung stand. Dieses konnte im Rahmen der überregionalen Literaturversorgung per Fernleihe deutschlandweit ausgeliehen werden. Die SSGs waren nicht nur printbasiert, sondern verfolgten auch eine forschungsunabhängige Erwerbungspolitik, um auch diejenigen Publikationen zu akquirieren, die erst künftiger Forschung dienen könnten.
Angesichts der digitalen Transformation in Wissenschaft und Bibliothek musste sich das etablierte kooperative System der überregionalen Literaturversorgung grundlegend wandeln. Die SSGs wurden seit 2015 zu Fachinformationsdiensten (FIDs) weiterentwickelt, die zwar weiterhin die lokalen Bibliotheken an Universitäten und Forschungseinrichtungen durch zentrale Erwerbung gedruckter Literatur ergänzen, die aber insbesondere auf die ortsunabhängige Versorgung der Wissenschaft mit digitalen Forschungsressourcen und Dienstleistungen auch für aktuelle Forschungstrends zielen. Die geschichtswissenschaftlichen SSGs stellen inzwischen ein reiches Portfolio von Volltextdatenbanken für Forschungsliteratur – und für Quellen – zur Verfügung.
Im Folgenden wird die Entwicklung der Volltexterkennung (Kap. 1.1) in Bezug auf die Konzepte der Verteilten deutschen Nationalbibliothek und der Verteilten nationalen Forschungsbibliothek (Kap. 1.2) für historische Volltextdatenbanken für Quellen und Forschungsliteratur beschrieben. Dabei werden zunächst zentrale Institutionen vorgestellt, die relevante Projekte zu Digitalisierung, Volltexterkennung, Volltextdatenbanken und Digitalen Editionen tragen.
Die Philosophische Fakultät der Universität zu Köln gehört zu den führenden Standorten im Bereich digitale Geschichtswissenschaften und DH in Deutschland: Hier wurde in der Tradition der historischen Fachinformatik 1997 die Professur für Historisch-Kulturwissenschaftliche Informationsverarbeitung (HKI) eingerichtet, die von Manfred Thaller geprägt wurde, der auch den Prozess der Digitalisierung des schriftlichen Kulturerbes an Bibliotheken begleitete. Das Institut für Digital Humanities (IDH) widmet sich der historisch-kulturwissenschaftlichen und sprachlichen Informationsverarbeitung und arbeitet mit dem Data Center für Digital Humanities (DCH) zusammen, das Geisteswissenschaftlerinnen und Geisteswissenschaftler bei der Sicherung, Verfügbarkeit und Präsentation von Forschungsdaten und -ergebnissen berät. Es ist darüber hinaus an geisteswissenschaftlichen Konsortien der Nationalen Forschungsdateninfrastruktur (NFDI) beteiligt. Beide Institutionen sind Teil des 2009 gegründeten Cologne Center for eHumanities (CCeH), das als Kompetenzzentrum für DH-Projekte über Köln hinauswirkt.
Mit der Kölner Schule Thallers verbunden ist Patrick Sahle, der mit zahlreichen Publikationen und Projekten der DH[58] hervorgetreten ist und diesen Forschungsbereich an der Bergischen Universität Wuppertal vertritt.
Wie Köln besitzt das 1998 gegründete Kompetenzzentrum – Trier Center for Digital Humanities eine reiche Tradition. Mit diesem kooperiert das Fach Computerlinguistik und Digital Humanities im Fachbereich II Sprach-, Literatur- und Medienwissenschaften der Universität.
Neben Köln, Wuppertal und Trier besitzt die Westfälische Wilhelms-Universität Münster einen etablierten Schwerpunkt im Bereich der DH. Während das Center for Digital Humanities (CDH) einen Interessensverbund von digital Forschenden der Fachbereiche Geisteswissenschaften und Informatik bildet, bietet das Service Center for Digital Humanities (SCDH) konkrete Unterstützung bei Planung und Durchführung einschlägiger Projekte. Die institutionelle Einbindung des SCDH in die Universitäts- und Landesbibliothek Münster zeigt die enge Verbindung zwischen Bibliothek und Fachwissenschaften auf dem Feld der DH.
Aus einer ähnlichen Verbindung ist das Würzburger Zentrum für Philologie und Digitalität „Kallimachos“ (ZPD) hervorgegangen. Als zentrale wissenschaftliche Einrichtung der Universität verbindet es Geisteswissenschaften, Informatik und DH in hervorragender Weise, wie die hier entstandenen digitalen Editionen und Volltextdatenbanken zeigen.[67]
Ein Beispiel für ein außeruniversitäres Forschungsinstitut, das in DH-basierten Projekten über lange Erfahrungen verfügt, ist das Leibniz-Institut für Bildungsmedien|Georg-Eckert-Institut (GEI). Seine bis in das 17. Jahrhundert zurückgehende Sammlung historischer Schulbücher wird seit 2009 digitalisiert über die digitale Schulbuchbibliothek GEI-Digital publiziert.
Auf der Digitalisierung der Verzeichnisse deutscher Drucke des 16., 17. und 18. Jahrhunderts innerhalb der Verteilten deutschen Nationalbibliothek (Kap.1.2) setzt seit 2014 das Projekt OCR-D auf.[71] Da große Teile der Nationalbibliografien VD16, VD17 und VD18 inzwischen mit Volldigitalisaten angereichert sind, ist durch die Entwicklung im Bereich OCR eine Volltexttransformation des gesamten gedruckten deutschen schriftlichen Kulturerbes möglich geworden, indem aus den als Bilddateien gespeicherten Digitalisaten durchsuchbare Textdateien erzeugt werden: Die wissenschaftliche Nutzbarkeit digitalisierter Drucke insbesondere im Kontext der DH setzt zwingend maschinenlesbare Volltexte voraus. Künftig sollen innerhalb der digitalen Verteilten deutschen Nationalbibliothek nicht nur umfassende Volltextsuchen, sondern auch differenzierte Analysen und Bearbeitungen der Textquellen mit Werkzeugen der DH im distant reading möglich sein.
Mit der Open Source OCR-D-Software, deren Prototyp 2020 fertiggestellt wurde, können Modelle für eine automatische Transkription von Texten entwickelt werden, die mit der Vielfalt der historischen Layoutvarianten, der Drucktypen, der Orthographie und der Sprache umgehen können.
Um Technologien der automatischen Texterkennung möglichst niederschwellig einsetzen zu können, arbeitet das Zentrum für Philologie und Digitalität „Kallimachos“ (ZPD) gegenwärtig daran, in den Projekten OCR4all und OCR4all-libraries – Volltexterkennung historischer Sammlungen unterschiedliche freie OCR-Tools in einem standardisierten Workflow zusammenzuführen.
Sämtliche Projekte, die von universitären und außeruniversitären Instituten sowie von Bibliotheken konzipiert und realisiert werden, bedürfen einer zuverlässigen Finanzierung: Hierbei spielt der DFG-Förderbereich Wissenschaftliche Literaturversorgungs- und Informationssysteme (LIS) eine herausragende Rolle. Die DFG-geförderten Projekte und Forschungsinitiativen zu Digitalisierung und Volltexterkennung als Grundlage für die Entwicklung von Volltextdatenbanken dokumentiert die Datenbank GEPRIS.
Neben dem DFG-geförderten nationalen Projekt OCR-D wird die Forschung zum Thema Volltexterkennung auch auf Landesebene öffentlich unterstützt: Das an den Universitätsbibliotheken Mannheim und Tübingen angesiedelte Projekt OCR-BW beispielsweise hat zum Ziel, Bibliotheken, Universitäten und Forschende in Baden-Württemberg bei der Implementierung und Anwendung von automatischer Texterkennungs- und Transkriptionssoftware zu unterstützen.[77] Neben der Software OCR-D erforscht OCR-BW die Software-Lösungen und OCR-Engines Tesseract, OCRmyPDF, Ocropus, Kraken, Calamari, eScriptorium und Transkribus.
Zum Abschluss dieses Kapitels informieren wenige Hinweise darüber, wie man sich über aktuelle Themen, Projekte sowie wichtige Autorinnen und Autoren innerhalb des Fachdiskurses zu Volltextdatenbanken im Kontext digitaler Geschichtswissenschaften informieren kann. Relevant ist insbesondere die spezifische inhaltliche Perspektive: Handelt es sich um eine eher geschichtswissenschaftliche, informationswissenschaftliche oder bibliothekarische Fragestellung?
Aus geschichtswissenschaftlicher Sicht bietet der FID historicum.net einen der wichtigsten Rechercheeinstiege auch für Methoden und Werkzeuge der digitalen Geschichtswissenschaften. Der FID Buch-, Bibliotheks- und Informationswissenschaft (FID BBI) informiert über Spezialliteratur und Forschungsressourcen aus drei Kerndisziplinen, deren Anwendung auch in den digitalen Geschichtswissenschaften relevant sein können.
Während diese beiden Portale für die Recherche nach selbstständiger (Monografien) und unselbstständiger (Aufsätze) Literatur geeignet sind, bietet die Zeitschriftendatenbank (ZDB) einen vollständigen Überblick über die periodisch erscheinende Literatur der betreffenden Disziplinen.
Ein Beispiel ist die Zeitschrift für digitale Geisteswissenschaften (ZfdG). Sie bietet einen Einblick in den interdisziplinären Fachdiskurs der mit digitalen Ressourcen, Methoden und Konzepten arbeitenden Geisteswissenschaften, zu denen die Geschichtswissenschaften gehören.
Ein anderes Beispiel ist RIDE – A review journal for digital editions and resources mit einem Überblick über Konzepte und Technologien aktueller digitaler Editionen. In seiner Schriftenreihe (SIDE) behandelt das Institut für Dokumentologie und Editorik (IDE) die Anwendung innovativer Informationstechnologien für die Arbeit mit historischen Dokumenten und Texten. In Kooperation mit dem IDE und der Bergischen Universität Wuppertal wird von Patrick Sahle der Catalog of Digital Scholarly Editions herausgegeben, der eine gezielte Recherche nach digitalen Editionen ermöglicht.
Aktuelle Informationen über die Entwicklung historischer Volltextdatenbanken bietet auch der Blog des Verbandes DHd – Digital Humanities im deutschsprachigen Raum. Er entstand auf Initiative der Forschungsverbünde TextGrid und DARIAH-DE sowie des Max-Planck-Instituts für Wissenschaftsgeschichte Berlin.
Neben dem in Fachjournalen und Wissenschaftsblogs schriftlich geführten Fachdiskurs ist der direkte persönliche Austausch in Fachverbänden entscheidend. Für den Fachdiskurs in Deutschland am wichtigsten ist der 2012 an der Universität Hamburg gegründete Verband DHd – Digital Humanities im deutschsprachigen Raum. Dieser richtet jährliche Tagungen aus, ist Herausgeber der genannten Zeitschrift für digitale Geisteswissenschaften (ZfdG) und bearbeitet in zahlreichen Arbeitsgruppen zentrale Themen der DH – die AG OCR beispielsweise Volltextdatenbanken. Innerhalb des Verbands der Historiker und Historikerinnen Deutschlands (VHD) befasst sich die Arbeitsgemeinschaft Digitale Geschichtswissenschaft mit den Themen DH, Forschungsdaten, digitale Methoden oder digitale Quellenkritik.
Die vorausgegangene Skizze des State of the Art der Digitalisierung, digitalen Transformation und Methodenentwicklung in Bibliotheken und digitalen Geschichtswissenschaften zeigt, in welche Nutzungsszenarien historische Volltextdatenbanken eingebettet sind. Historische Volltextdatenbanken für Quellen und Forschungsliteratur werden als integrale Bestandteile offener, vernetzter Text- und Datenwelten verstanden, die über folgende Qualitäten verfügen sollten:
– Digitalisierung nach DFG-Standards.
– Beschreibung der Digitalisate durch Metadaten im Format METS/MODS für den Datenaustausch über APIs.
– Downloadmöglichkeit der Digitalisate mitsamt Roh- und Metadaten auf Grundlage der Prinzipien des Open Access, (Linked) Open Data sowie der FAIR-Prinzipien (findable, accessible, interoperable, reusable).
– Volltextindexierung und Volltexterkennung (HTR, OCR) für quantitative Volltextanalysen im distant reading, die ein qualitatives close reading auf eine neue Grundlage stellen.
– Publikation der Digitalisate im Open Access oder unter möglichst offenen Lizenzen zur Nachnutzbarkeit in Open Science-Szenarien.
– Referenzierbarkeit der Digitalisate durch stabilen Uniform Resource Name (URN) oder Uniform Resource Identifier (URI).
– Möglichkeit der Einbindung in virtuelle Forschungsumgebungen und (kollaborativen) Weiterverarbeitung der Digitalisate mit quantitativen und qualitativen Forschungsansätzen durch Tools und Methoden der DH (z.B. Annotationen, Visualisierungen).
– Möglichkeit vergleichenden Arbeitens, z. B. durch Verwendung des International Image Interoperability Framework (IIIF), um Digitalisate von Texten und Objekten institutionsübergreifend austauschen und standortunabhängig in unterschiedlichen Viewern präsentieren sowie mit Bildbearbeitungs- und Annotationstools bearbeiten zu können.
– Auffindbarkeit durch bibliothekarisch-formale und wissenschaftlich-intellektuelle Erschließung mit geeigneten normierten Metadaten.
– Vernetzung von Quellen und Forschungsliteratur miteinander.
Speziell für Volltextdatenbanken für historische Originalquellen wie Texte oder kulturelle Artefakte empfiehlt sich:
– Erschließung durch wissenschaftliche Beschreibungen (z.B. Kataloge).
– Verknüpfung mit Editionen (gedruckt, digital).
– Verknüpfung mit Forschungsliteratur (gedruckt, digital).
– Kontextualisierung mit weiteren relevanten Texten und Objekten (gedruckt, digital) in Fach- und Kulturportalen.
Speziell für Volltextdatenbanken für digitalisierte und genuin digitale Forschungsliteratur empfiehlt sich:
– Erschließung durch bibliothekarische Metadaten und Normdaten.
– Erschließung durch Thesauri, Fachklassifikationen oder intellektuelle Inhaltserschließung.
– Verknüpfung über Linkresolver mit lokalen Bibliothekskatalogen.
– Verknüpfung mit digitalisierten historischen Originalquellen.
�unable to handle picture here, no embed or linkAbbildung 6. Möglichkeiten der Erschließung und Nutzung von digitalisierten Texten und Quellen in VolltextdatenbankenWelche dieser Nutzererwartungen historische Volltextdatenbanken bereits erfüllen und wo weiterhin Entwicklungsbedarf besteht, wird im folgenden Kapitel exemplarisch gezeigt.
Eine auch nur annähernd vollständige Bestandsaufnahme historischer Volltextdatenbanken kann im Rahmen dieses Guides nicht geleistet werden. Der praxisorientierte Überblick ist vor dem Hintergrund der Konzepte der Verteilten deutschen Nationalbibliothek und der Verteilten nationalen Forschungsbibliothek (Kap. 1.2) untergliedert nach Volltextdatenbanken für Forschungsliteratur (Kap. 2.5) einerseits, für Quellen und Quelleneditionen (Kap. 2.6) andererseits. Hinter beiden Konzepten stehen Institutionen, die mit konkreten historischen Volltextdatenbanken verbunden sind. Unterschieden wird ferner zwischen umfassenden Portalen und einzelnen Volltextdatenbanken. Die folgende Übersicht präsentiert schwerpunktmäßig Volltextdatenbanken für Quellen nach historischen Epochen, Regionen und Themen. Die diesen Guide ergänzende Linkliste beinhaltet weitere ausgewählte Ressourcen.
Wie in der Einführung (Kap. 1.1) beschrieben, sind historische Volltextdatenbanken in unterschiedlichen Kontexten entstanden und durch öffentliche Wissenschaftseinrichtungen und kommerzielle Verlage gleichermaßen geprägt: Bibliotheken beispielsweise bieten einerseits in Volltextdatenbanken digitalisierte oder genuin digitale Texte und Digitalisate von Quellen mitsamt Metadaten im Open Access an, sie finanzieren andererseits durch unterschiedliche Lizenzierungsmodelle den Zugang zu kommerziellen digitalen Produkten von Verlagen im Closed Access. Während Universitätsbibliotheken diese Ressourcen allein oder konsortial ausschließlich für ihre eigenen Forschenden, Lehrenden und Studierenden lizenzieren, ermöglichen Landes- und Staatsbibliotheken diese Zugänge für eine wissenschaftlich interessierte Öffentlichkeit außerhalb von Wissenschaftsinstitutionen.
Sowohl wissenschaftliche wie auch private Nutzerinnen und Nutzer in Deutschland profitieren von den Nationallizenzen. Die DFG finanzierte 2004 – 2010 den Erwerb von Lizenzen, um Studierenden, Wissenschaftlern und der interessierten Öffentlichkeit den freien Zugriff auf kostenpflichtige elektronische Verlagsprodukte zu ermöglichen. Die Nationallizenzen wurden 2011 durch Allianz-Lizenzen abgelöst, für die sich Bibliotheken in Konsortien zusammenfanden, um ausgewählte Datenbanken zu lizenzieren.
Etwas komplexer ist die Ablösung der Sondersammelgebiete (SSGs) durch Fachinformationsdienste (FIDs): Während auf die gedruckte Literatur der SSGs jedermann zugreifen konnte, sind die FID-Lizenzen nur für fachlich definierte Communities zugänglich (Kap. 1.2). Für die Geschichtswissenschaften sind mehrere Bibliotheken als Träger von Fachinformationsdiensten relevant, beispielsweise die Bayerische Staatsbibliothek für die Alte Geschichte, die Geschichte Deutschlands, Österreichs, der Schweiz, Frankreichs, Italiens und die Technikgeschichte in Kooperation mit dem Deutschen Museum (Abb. 5).
Die Situation, dass digitale Forschungsressourcen wie historische Volltextdatenbanken unterschiedlichen Zugangsmodalitäten unterliegen, bestimmt ihre Nutzung grundlegend und erfordert eine souveräne Orientierung auf diesem Feld. Da seit Beginn der Digitalisierung und der digitalen Transformation die gesellschaftliche Relevanz, die der freie Zugang zu wissenschaftlichen Informationen besitzt, immer deutlicher wurde, liegt in der weiteren Transformation hin zum Open Access eine der großen Herausforderungen der Zukunft.
So heterogen die analogen Vorläufer der historischen Volltextdatenbanken sind, so wenig eindeutig, ist eine Definition des Begriffs „Volltextdatenbank“. Aus geschichtswissenschaftlicher Praxis und informationstechnologischer sowie bibliothekarischer Theorie lässt sich dennoch ein gemeinsames Kernverständnis von Volltextdatenbanken herleiten. Im Allgemeinen sind Volltextdatenbanken Sammlungen elektronischer Volltexte mit bibliografischen und weiteren Metadaten. Historische Volltextdatenbanken im Speziellen sind Datenbanken, in denen für die Geschichtswissenschaften relevante einzelne Texte oder Sammlungen von Quellentexten, Quelleneditionen und Forschungsliteratur präsentiert werden. Als Volltextdatenbanken können aber auch Datenbanken für nicht-textuelle Quellen, Objekte und kulturelle Artefakte verstanden werden, sofern diese Textträger sind und von Transkriptionen begleitet werden. Beispiele hierfür sind Texte auf unterschiedlichen Trägern wie Stein, Papyrus, Pergament oder historische Karten. Dabei ist es unerheblich, ob die Texte lediglich als Images digitalisiert sind oder ob durch eine implementierte OCR-Erkennung eine Volltextsuche möglich ist.
Diese weite Definition möchte dem material turn innerhalb der Geschichtswissenschaften gerecht werden: (Text-) Objekte sind genauso wichtig wie reine Texte, denn auch sie vermögen durch ihr narratives Potenzial Geschichte zu erzählen – wenn sie von Historikerinnen und Historikern angemessen entziffert werden.
Objekte, bei denen Texte keinerlei Rolle spielen, werden hingegen in der Regel in Bilddatenbanken erfasst und spielen hier keine Rolle.
�unable to handle picture here, no embed or linkAbbildung 7. Datenbank-Infosystem (DBIS) – Fachübersicht (https://dbis.ur.de//fachliste.php?lett=l, 20.12.2023)Das Datenbank-Infosystem (DBIS) ist das wichtigste Verzeichnis wissenschaftlicher Datenbanken im deutschen Sprachraum.
So heterogen die in DBIS verzeichneten Datenbanken sind, so gibt es doch formale Kriterien für die Aufnahme: Umfang der Datenmenge, langfristige Verfügbarkeit, kontinuierliche Pflege und Aktualisierung, Wissenschaftlichkeit, Seriosität der Inhalte und Herausgeber. In DBIS nicht aufgenommen werden Linklisten, Literaturlisten im HTML- oder PDF-Format, einzelne E-Books oder E-Journals sowie Bibliotheks-OPACs. DBIS ermöglicht sowohl eine bibliotheksübergreifende als auch eine lokale Sicht auf die Datenbanken sämtlicher Wissenschaftsdisziplinen und ihre Zugangsmodalitäten. Unter den etwa 2.600 Datenbanken allein für das Fach Geschichte finden sich knapp 1.060 historische Volltextdatenbanken – ein deutlicher Beleg für die kontinuierlich steigende Bedeutung von Volltextdatenbanken für das geschichtswissenschaftliche Arbeiten.
Unter die in DBIS als „Volltextdatenbank“ klassifizierten Produkten werden inhaltlich und formal heterogene Angebote subsumiert. DBIS versteht als „Volltextdatenbank“ eine „Datenbank jeglicher Art mit direkten Zugriffen auf Volltexte.“ Entsprechend dieser weiten Definition werden auch Portale, in denen Volltexte nur einen Teil des Angebotes darstellen, oder Datenbanken, die keine Texte, sondern audiovisuelle Medien beinhalten, subsumiert. Des Weiteren sind Vollständigkeit der Texte sowie ihre Erschließung durch Abstracts oder Schlagwörter zentrale Kriterien. In DBIS firmieren als „Volltextdatenbanken“ sowohl Datenbanken mit durch Metadaten erschlossenen Texten, die lediglich als Image-Digitalisate vorliegen, als auch Datenbanken mit digitalisierten Texten, die mit OCR-Software bearbeitet wurden und echte Volltextsuchen ermöglichen.
Ob in den von DBIS als Volltextdatenbanken für Quellen, Quelleneditionen und Forschungsliteratur klassifizierten Produkten eine Volltextsuche in den mit HTR/OCR bearbeiteten Bilddigitalisaten von Originalquellen (Inschriften, Handschriften, Inkunabeln, Drucke) oder digitalisierter Forschungsliteratur möglich ist, ist produktabhängig. Beispielsweise werden die Verzeichnisse der im deutschen Sprachraum erschienenen Drucke (VD16, VD17 und VD18) als „National- bzw. Regionalbibliografie“ klassifiziert, im Fall des VD17 jedoch zusätzlich als „Volltextdatenbank“. Eine Volltextsuche ist im VD17 jedoch in Zukunft erst dann möglich, wenn die Volltexttransformation der VD’s im Rahmen des Projektes OCR-D insgesamt realisiert ist. Ein anderes Beispiel ist die Datenbank IKAR-Landkartendrucke vor 1850, die als Fachbibliografie und zugleich als Volltextdatenbank klassifiziert ist, obwohl keine Volltextsuche in den Karten selbst möglich ist. Diese Beispiele zeigen, dass die Klassifizierung „Volltextdatenbank“ in DBIS uneinheitlich ist und keinen Rückschluss erlaubt, ob im Einzelfall tatsächlich eine Volltexterkennung durchgeführt wurde.
�unable to handle picture here, no embed or linkAbbildung 8. Datenbank-Infosystem (DBIS) – erweiterte Suche (https://dbis.ur.de//suche.php?bib_id=alle&colors=3&ocolors=40, 27.04.2024)Mit der „erweiterten Suche“ lassen sich in DBIS gezielt Datenbank-Typen für unterschiedliche Fächer auswählen. Aus der Produktübersicht wird deutlich, unter welchem Lizenztyp eine Datenbank zur Verfügung steht: eine Ampelsymbolik kennzeichnet die unterschiedlichen Zugangsarten.
�unable to handle picture here, no embed or linkAbbildung 9. Datenbank-Infosystem (DBIS) – Zugangsarten und Ampelsymbolik (https://dbis.ur.de//dbliste.php?bib_id=ubfre&colors=31&ocolors=40&lett=a, 27.04.2024)Nahezu sämtliche der im Folgenden besprochenen Produkte sind in DBIS verzeichnet, inhaltlich beschrieben und im Hinblick auf die institutionelle Lizenzierung definiert. Daher empfiehlt sich DBIS als erster Zugriff auf Volltextdatenbanken im Recherchealltag. Um die Lektüre dieses Überblicks zu erleichtern, wird sowohl in den Fußnoten als auch in der separaten Liste relevanter Volltextdatenbanken jedoch die direkte Verlinkung auf die Ressource präferiert.
Neben der Fachsicht innerhalb von DBIS empfiehlt sich für Historikerinnen und Historiker der Einstieg in die Fachinformationsrecherche über die jeweiligen FIDs als Teile der Verteilten nationalen Forschungsbibliothek. Diese tragen dafür Sorge, dass die relevanten Forschungsressourcen, zu denen auch die Volltextdatenbanken gehören, deutschlandweit zur Verfügung stehen. Hierdurch ergänzen sie das System der Nationallizenzen. Auch wenn die FID-Lizenzen für die Geschichtswissenschaften in DBIS erfasst sind, finden sich auf den Portalen der einzelnen FIDs vielfältige weitere Fachinformationen.
Für die Geschichtswissenschaften spielen Kulturportale sowie digitale Bibliotheken, die das kulturelle und wissenschaftliche Erbe öffentlich zugänglich machen, eine wichtige Rolle. Eine digitale Bibliothek verfolgt grundsätzlich dieselben Ziele wie eine papierene Bibliothek: Sammlung, Strukturierung, Erschließung und Archivierung von digital(isiert)en textuellen und kulturellen Inhalten.
Digitale Bibliotheken können zugleich Virtuelle Bibliotheken sein, die über keine eigenen Bestände verfügen, sondern als elektronisches Informationssystem Metadaten und Volltexte aus unterschiedlichen Quellen unter einer einheitlichen Oberfläche zusammenführen und recherchierbar machen. Im Folgenden werden die wichtigsten regionalen, nationalen und internationalen Kulturportale und digitale Bibliotheken mit dem Schwerpunkt auf historischen Schriftquellen vorgestellt.
Europeana, das Kulturportal Europas, setzt auf den nationalen Kultur- und Wissenschaftsinstitutionen mit ihren digitalisierten Sammlungen auf. Da die Erschließung heterogener Quellen unterschiedlicher Institutionen nicht immer homogen ist und nicht sämtliche Metadaten aus den Ursprungsdatenbanken in Europeana abgebildet werden, empfiehlt sich für qualitativ hochwertige Rechercheergebnisse immer auch eine differenzierte Suche in den Nachweissystemen der bestandshaltenden Institutionen selbst.
Die Deutsche Digitale Bibliothek (DDB) ist bei der Deutschen Nationalbibliothek (DNB) und der Stiftung Preußischer Kulturbesitz angesiedelt. Als nationales Portal weist sie das kulturelle Erbe deutscher Gedächtnisinstitutionen – beispielsweise Bücher, Archivalien, Bilder, Skulpturen, Tondokumente, Filme, Noten – zentral nach und stellt diese als nationaler Aggregator der Europeana zur Verfügung. Wie in der Europeana stehen in der DDB neben bibliografischen Metadaten auch Volltexte und Digitalisate zur Verfügung, die jedoch nicht immer für eine Volltexterkennung aufbereitet sind. Innerhalb der DDB weist das Archivportal-D digitalisiertes Archivgut, Findbücher und Informationen zu deutschen Archiven zentral nach.
Die DDB baut ihrerseits auf den Kulturportalen der Bundesländer auf, beispielsweise:
– Baden-Württemberg: LEO-BW – Landeskunde entdecken online.
– Bayern: bavarikon – Kultur und Wissensschätze Bayerns.
– Hessen: LAGIS – Landesgeschichtliches Informationssystem.
– Niedersachsen: Kulturerbe Niedersachsen.
– Sachsen: Sachsen.digital.
Insbesondere für die Regionalgeschichte sind diese Landesportale von großer Bedeutung, da sie häufig auch über unterschiedliche Themenportale verfügen.
Wie die DNB bieten auch Nationalbibliotheken anderer Länder übergreifende Portale und spezifische Angebote, in denen für die eigene nationale Geschichte relevante Quellen und Forschungsliteratur digitalisiert und in Volltextdatenbanken veröffentlicht werden. Für die historische Forschung lassen sich hier vielfältige Entdeckungen machen.
Nach dem Vorbild der Europeana entstand in den USA die Digital Public Library of America (DPLA) mit Digitalisaten von Kulturgütern aus Bibliotheken, Archiven und Museen der USA unter freien Lizenzen.
Die größte und bedeutendste Bibliothek der USA, die Library of Congress (LoC) in Washington, präsentiert in ihren Digital Collections zentrale Dokumente der US-amerikanischen Geschichte, darunter Handschriften, seltene historische Drucke und Bücher, Zeitungen, Karten, Noten, Ton- und Filmdokumente aus sämtlichen Bundesstaaten.
In Europa digitalisiert die British Library (BL) in London als größte Bibliothek der Welt nach der Library of Congress (LoC) ihre reichen Sammlungen und präsentiert diese in ihren Digital Collections– ein exzellenter Einstieg in die Recherche nach Schriftquellen wie Handschriften, Autographen, historischen Drucken, Büchern, Zeitungen, Karten, audiovisuellen Dokumenten und Forschungsliteratur zur Geschichte Englands und des Commonwealth.
Stellvertretend für die übrigen Nationalbibliotheken Europas sei die Bibliothèque nationale de France (BnF) in Paris genannt, die im Projekt Gallica gemeinsam mit zahlreichen Partnerinstitutionen eine digitale Bibliothek für das Kulturerbe Frankreichs aufbaut, das zu großen Teilen bereits im Volltext durchsuchbar ist – ein ausgezeichneter Einstieg in die französische Geschichte.
Neben diesen regionalen, nationalen und internationalen Kulturportalen gibt es zahlreiche digitale Bibliotheken mit speziellen Volltextdatenbanken, die für historische Forschungen von Interesse sein können. Als älteste digitale Bibliothek der Welt gilt das 1971 begründete Project Gutenberg, das zum Ziel hat, urheberrechtsfreie Bücher mit literarischen Texten weltweit zugänglich zu machen. Wurden am Beginn des Projekts ausgewählte Bücher von Freiwilligen manuell abgetippt und die Transkriptionen korrigiert, bevor diese im Internet veröffentlicht wurden, ermöglichte die kontinuierliche Verbesserung von Scan-Technik und Texterkennungssoftware ein immer schnelleres Wachstum dieser digitalen Bibliothek. Während im Project Gutenberg vorwiegend englischsprachige Bücher enthalten sind, bietet das Projekt Gutenberg-DE gemeinfreie deutschsprachige literarische Werke.[119]
Unter den kommerziellen Anbietern digitaler Bibliotheken auch historischer Bücher, in denen Volltextsuchen möglich sind, ist Google Books am bekanntesten. Mit seiner 1997 online gegangenen Suchmaschine wollte Google nicht nur die Informationen des World Wide Web erschließen. Die Idee des parallel entwickelten Library Projects war, das weltweite gedruckte kulturelle Erbe der „Gutenberg-Galaxis“ mit seinem darin niedergelegten menschlichen Wissen systematisch zu digitalisieren, mit OCR zu bearbeiten und eine globale Volltextsuche über sämtliche Textgattungen und Epochen zu spannen. Im Unterschied zum Ziel der Arbeitsgemeinschaft Sammlung Deutscher Drucke (AG SDD), das schriftliche Kulturerbe an deutschen Bibliotheken systematisch zu erfassen und zu digitalisieren, war Googles Ziel ein globales. Daher kooperierte der Internetkonzern einerseits mit kommerziellen Verlagen, andererseits mit wissenschaftlichen Bibliotheken weltweit – im deutschen Sprachraum mit der Österreichischen Nationalbibliothek Wien, mit der Bayerischen Staatsbibliothek München und mit der Staatlichen Bibliothek Regensburg. Google stellte die Digitalisate her – die Bibliotheken erhielten von Google eine digitale Kopie eines jeden gescannten Buches aus ihren Sammlungen.
Das von Google von Anfang an verfolgte Ziel ist jedoch nicht ohne Hindernisse zu erreichen – zu komplex ist die urheberrechtliche Situation im Falle der jüngeren Texte. Hierin liegt der Grund, dass lediglich ältere Bücher, deren urheberrechtlicher Schutz erloschen ist, frei zugänglich sind, während in allen anderen Fällen ein stark eingeschränkter Zugriff auf die Volltexte möglich ist: Google Books unterscheidet daher zwischen „Vollansicht“, „Eingeschränkte Vorschau“, „Auszugsansicht“ und „Keine Vorschau verfügbar“. Im Jahr 2019 gab Google Books anlässlich seines 15-jährigen Bestehens bekannt, mehr als 40 Millionen Bücher in mehr als 400 Sprachen digitalisiert zu haben.
Auf Grundlage dieses monumentalen Volltextcorpus lassen sich vielfältige quantitative Analysen durchführen. Mit dem Google Books Ngram Viewer beispielsweise lässt sich erkennen, wann ein bestimmter Begriff innerhalb von Google Books erstmals fassbar wird und wie sich seine Verwendung im Laufe der Zeit verändert hat.
Am Beispiel von Google Books werden zugleich die Grenzen einer wissenschaftlichen Recherche lediglich auf Grundlage einer Volltextsuche in Texten mit Volltextindexierung deutlich. Google hatte seine Suchmaschinentechnologie, die auf der Indexierung des World Wide Web beruhte, auf das digitalisierte gedruckte schriftliche Kulturerbe übertragen. Da eine systematische, bibliothekarische und wissenschaftliche Erschließung der einzelnen, von Google digitalisierten Bücher fehlt, muss eine Recherche in Google Books mit einer Stichwortsuche auskommen. Die gewählten Suchbegriffe sollten in unterschiedlichen Sprachen formuliert werden, um Zugriff auf die jeweils nationale Literatur zu erhalten.
Hier bieten Bibliotheken noch immer einen deutlichen Mehrwert: Sie verfügen über fachnahe Konzepte der qualitativen Strukturierung von Informationen und erschließen ihre Texte mit differenzierten Metadaten wie Schlagwörtern oder Fachthesauri, die für wissenschaftliche Recherchen notwendig sind. Die Verknüpfung mit Normdaten ermöglicht eine gezielte Referenzierbarkeit und Vernetzung von Texten, Objekten oder Daten. Insofern bietet Google Books zwar eine attraktive Ergänzung zu geschichtswissenschaftlichen Volltextdatenbanken, doch sollte man sich auch der Grenzen bewusst sein. Unter dem Aspekt der Sichtbarkeit des globalen kulturellen und wissenschaftlichen gedruckten Erbes innerhalb digitaler Bibliotheken ist zu beachten, dass eine Recherche mit der Suchmaschine Google unter Berücksichtigung von Google Books ein Ranking der Ergebnisse zeigt, in dem englischsprachige Literatur dominiert. Daher empfiehlt sich die gleichzeitige Konsultation von Kulturportalen und digitalen Bibliotheken wie der Europeana oder der DDB.
Wikisource, eine Sammlung gemeinfreier oder unter einer freien respektive Creative-Commons-Lizenz (CC-BY bzw. CC-BY-SA) stehender Texte, wird häufig unbewusst genutzt, da diese mit Wikipedia verbunden ist. Für die Geschichtswissenschaft ist Wikisource von besonderer Bedeutung, da insbesondere ältere Texte mit dem Status von historischen Quellen Berücksichtigung finden. Grundlage der in Wikisource präsentierten Texte sind Erstausgaben, Ausgaben letzter Hand oder kritische Editionen, so dass wissenschaftliche Qualität gewährleistet ist. Aber auch digitalisierte geschichtswissenschaftliche Zeitschriften und zahlreiche Volltexte gehören zu den Ressourcen für Historikerinnen und Historiker.
Nicht nur eine digitale Bibliothek für Volltexte von Büchern, Musik, Filmen, Software oder Bildern, sondern zugleich ein Dienst, der Webseiten in unterschiedlichen Versionen speichert, ist das 1996 gegründete gemeinnützige Internet Archive. Da es nicht möglich ist, das gesamte World Wide Web in allen Zuständen dauerhaft zu archivieren, bietet die Speicherung von „Momentaufnahmen“ dennoch einen breiten Zugriff auf Webseiten, die zeitweise im Internet verfügbar waren – dieser erfolgt mit Hilfe der Wayback Machine. Ein Spiegelserver des in San Francisco ansässigen Internet Archive findet sich übrigens in der Bibliotheca Alexandrina in Ägypten, am Ort der größten Bibliothek der antiken Welt.
Innerhalb des Million Book Project als Teilprojekt des Internet Archive werden gemeinfrei gewordene Bücher digitalisiert und in der Open Library publiziert. Hier soll in einem kollaborativen Ansatz jedes jemals publizierte Buch auf einer eigenen Webseite dokumentiert werden. Dabei kann zum gemeinfreien bibliografischen Nachweis auch der direkte Zugriff auf das Digitalisat mit dem Volltext treten. Im Unterschied zu Google Books mit der Digitalisierung auch urheberrechtlich geschützter Literatur konzentriert sich die Open Library auf gemeinfreie Bücher.
Ein gemeinsames Projekt von zahlreichen US-amerikanischen Universitätsbibliotheken sowie Forschungseinrichtungen aus der ganzen Welt ist die HathiTrust Digital Library. Bibliografische Datenbank und Repositorium digitalisierter Bücher zugleich, ist eine Volltextsuche in Millionen Dokumenten unterschiedlicher Fachbereiche möglich – die Geschichtswissenschaft bildet einen Schwerpunkt. Der aus dem Hindi und Urdu stammende Name „Hathi“ bedeutet übrigens „Elefant“: Diesem wird ein besonderes Gedächtnis nachgesagt – insofern gleicht er den Archiven und Bibliotheken als Gedächtnis der Menschheit.
Eine wichtige deutschsprachige Volltextbibliothek ist Zeno.org. Sie basiert auf der kommerziellen Reihe Digitale Bibliothek (CD’s, DVD’s) und umfasst Texte vom Anfang des Buchdrucks bis zum Beginn des 20. Jahrhunderts. Seit 2009 ist die Volltextsammlung Teil des Repositoriums von TextGrid, der Virtuellen Forschungsumgebung für die Geisteswissenschaften, und kann zur wissenschaftlichen Bearbeitung, beispielsweise in digitalen Editionen, genutzt werden.
Insbesondere für kulturgeschichtliche Fragestellungen relevant ist das Deutsche Textarchiv (DTA) als Referenzcorpus der neuhochdeutschen Sprache. Es umfasst etwa 1.500 sorgfältig ausgewählte und nach Erstausgaben digitalisierte Texte unterschiedlicher Disziplinen aus dem 17.–20. Jahrhundert. Im Konsortium Text+ der Nationalen Forschungsdateninfrastruktur (NFDI) ist das DTA als Repositorium und strukturiertes, linguistisch annotiertes Volltextcorpus historischer Texte eingebunden.
Ein Blick in die Welt der Archive und Museen rundet den Blick auf die für die Geschichtswissenschaften relevante Anbieter digitaler Bibliotheken und Volltextdatenbanken ab. Von nationaler Bedeutung für das deutsche Archivwesen ist das Bundesarchiv, die für Sicherung des Archivgutes der Bundesrepublik Deutschland und seiner Vorgängerstaaten zuständige Institution. Über seine (Volltext-) Datenbanken für Bilder, Filme, Töne und Karten ist die Recherche innerhalb der allgemeinen wie auch der speziellen Archivbestände möglich. Die beiden zentralen historischen Museen der Bundesrepublik Deutschland – das Deutsche Historische Museum (Berlin) und das Haus der Geschichte (Bonn) – präsentieren nicht nur Dauerausstellungen aus eigenen Beständen und zahlreiche Sonderausstellungen mit Leihgaben zu Themen der deutschen Geschichte. Ein gemeinsames Projekt beider Museen mit dem Bundesarchiv ist das Lebendige Museum Online (LeMO), in dem auch (Volltext-) Datenbanken eine zentrale Rolle spielen.
�unable to handle picture here, no embed or linkAbbildung 10. Kulturportale und digitale Bibliotheken (Auswahl)Lag der Fokus bis hierher auf retrodigitalisierten Texten, die für die Geschichtswissenschaft als ältere, gemeinfreie Forschungsbeiträge oder als Quellen interessant sein können, so wird im folgenden Kapitel ein kurzer Überblick über Volltextdatenbanken aktueller geschichtswissenschaftlicher Forschungsliteratur gegeben.
Portale und Volltextdatenbanken für Forschungsliteratur können hier nicht in der notwendigen Breite thematisiert werden. Hinweise zu relevanten Volltextdatenbanken finden sich in den Guides zu Epochen oder Regionen. Daher sei nur kursorisch auf wenige große fachübergreifende Ressourcen hingewiesen.
Eine der wichtigsten Volltextdatenbanken für Zeitschriften aus dem gesamten Spektrum der Geistes-, Kultur- und Sozialwissenschaften aus dem Zeitraum 1800–2000 ist das Periodicals Archive Online (PAO). Es bietet über eine differenzierte Recherchemaske den Zugriff auf 3 Millionen durch Abstracts erschlossene Artikel aus 700 Zeitschriften.
Unverzichtbar für die Recherche nach Fachartikeln internationaler Zeitschriften nicht nur aus den Geschichtswissenschaften ist die Volltextdatenbank Journal Storage (JSTOR). Enthalten sind internationale wissenschaftliche Zeitschriften vom ersten Jahrgang an – je nach Titel und lokaler Lizenz ist der Zugriff auf die aktuellen Hefte aufgrund einer moving wall nicht möglich. Das deutsche Pendant zu JSTOR ist das Volltextarchiv DigiZeitschriften mit deutschsprachigen Fachzeitschriften, unter denen die Geschichtswissenschaften mit etwa 350 Traditionszeitschriften vertreten sind.
Zu fachspezifischen Volltextdatenbanken bieten die einschlägigen FIDs, wie Propylaeum für die Alte Geschichte oder historicum.net für die mittlere und neuere Geschichte, weitere Hinweise. Auf fachübergreifende Ressourcen wie Google Books, das Internet Archive oder Hathi Trust und andere wurde bereits hingewiesen (Kap. 2.4). Weitere Hinweise finden sich in der kommentierten Linkliste Volltextdatenbanken.
Neben der Verteilten nationalen Forschungsbibliothek ist die Verteilte deutsche Nationalbibliothek Anbieter und Plattform historischer Volltextdatenbanken für Quellen und Quelleneditionen. Die nationalbibliografischen Verzeichnisse VD16, VD17 und VD18 sowie das zvdd sind vor allem für die deutsche Geschichte interessant – insbesondere durch die Perspektive ihrer geplanten Volltexttransformation im Rahmen des Projektes OCR-D. Die im Folgenden vorgestellten Volltextdatenbanken für historische Quellen berücksichtigen Produkte im Open wie im Closed Access.
Volltextdatenbanken für Quellen entstanden und entstehen dadurch, dass schriftbasierte Originalquellen wie Inschriften, Papyri, Handschriften oder Drucke digitalisiert und als Bilder in Datenbanken veröffentlicht werden. Im strengen Sinn handelt es sich in diesen Fällen aber zunächst (noch) nicht um „Volltextdatenbanken“ – die Quellen werden lediglich durch detaillierte Metadaten beschrieben. Erst die Entwicklung der Texterkennung für Handschriften (HTR) oder Drucke (OCR) ermöglicht im nächsten Schritt, aus den reinen Bilddigitalisaten echte Volltexte zu generieren, in denen recherchiert werden kann und deren Weiterverarbeitung innerhalb von DH-Szenarien möglich ist.
Mit Volltextdatenbanken digitalisierter Originalquellen sind Volltextdatenbanken für Quelleneditionen verbunden – vielfach werden diese nicht nur untereinander, sondern auch mit bibliografischen Datenbanken oder Volltextdatenbanken für Forschungsliteratur vernetzt.
Antike Textquellen können auf unterschiedlichen Trägern überliefert sein, beispielsweise in Stein gehauen als Inschriften oder handgeschrieben auf Papyri oder Pergament in Form von Rotuli oder Codices. Relevante Quellen für die Alte Geschichte sind jedoch nicht allein Textzeugnisse, sondern auch kulturelle Artefakte wie archäologische Funde.
Zentrales Rechercheportal für bibliografische Informationen, Beschreibungen, Digitalisate, Transkriptionen und Übersetzungen von Papyri, Ostraka oder Holztafeln aus bedeutenden internationalen Sammlungen ist papyri.info. Der Papyrological Navigator (PN) ermöglicht eine integrierte Recherche innerhalb unterschiedlicher Datenbanken, beispielsweise im Heidelberger Gesamtverzeichnis der griechischen Papyrusurkunden Ägyptens, in der Duke Databank of Documentary Papyri (DDbDP) und im Advanced Papyrological Information System (APIS). Letzteres weist Informationen (Bibliografien, Beschreibungen), Abbildungen (Digitalisate) oder Übersetzungen zu papyrologischen Materialien (Papyri, Ostraka, Holztafeln) aus internationalen Sammlungen nach.
Einen Überblick über die wichtigsten Papyrussammlungen Deutschlands bietet das Papyrus Portal. Es ermöglicht sowohl eine parallele Suche über einzelne Papyrus-Datenbanken als auch den Wechsel in lokale Präsentationen mit häufig differenzierteren Rechercheoptionen.
Epigraphische Textzeugnisse der Antike werden als archäologische Objekte ebenfalls in Volltextdatenbanken publiziert, die neben Beschreibungen der Inschriften mit spezifischen Metadaten auch Transkriptionen, Übersetzungen und Digitalisate umfassen. Ein Beispiel ist die Epigraphische Datenbank Heidelberg (EDH), die auf eine umfassende Dokumentation lateinischer und bilinguer (z.B. lateinisch-griechischer) Inschriften des Römischen Reiches zielt. Berücksichtigt werden insbesondere die außerhalb der großen Corpora publizierten Inschriften. Die Suchmaske ermöglicht eine differenzierte Recherche innerhalb des umfangreichen Materials – Inschriftentexte, Fotodokumentationen, Bibliografie und Geografie. Partner der EDH sind unter anderen die Epigraphik-Datenbank Claus/Slaby (EDCS), das Corpus Inscriptionum Latinarum (CIL),[150]Inscriptiones Graecae (IG), Searchable Greek Inscriptions (PHI Greek Inscriptions), Trismegistos (TM), Europeana EAGLE oder Ubi Erat Lupa (Lupa). Es ist zu beachten, dass papyrologische und epigraphische Quellen häufig in gemeinsamen Volltextdatenbanken erfasst sind.
Perseus Digital Library (PDL) ist eine der ältesten online verfügbaren geisteswissenschaftlichen Textsammlungen – mit Schwerpunkt auf der antiken Überlieferung. In der Kollektion Greek and Roman Materials bietet sie auf Grundlage zitierfähiger Editionen Volltexte klassischer griechischer und lateinischer Literatur, teilweise mit (englischen) Übersetzungen, die im Scaife Viewer miteinander verglichen werden können. Insbesondere Analysen historischer Begrifflichkeiten oder philologische Fragestellungen zum Wortgebrauch sind möglich.
Der Thesaurus Linguae Graecae (TLG) enthält klassische griechische Texte aus der Zeit zwischen etwa 800 v. Chr. und 600 n. Chr. sowie mittelalterliche historiographische, lexikographische und scholastische griechische Texte aus der Zeit zwischen etwa 600 n. Chr. und 1453 n. Chr. Die Suchmaske erlaubt komplexe Recherchen nach Autor, Werk, Datierung, Gattung, aber auch eine Volltextsuche innerhalb der Werke eines oder mehrerer Autoren. Die Darstellung der Texte erfolgt wahlweise in griechischen oder transliteriert in lateinischen Buchstaben. Die Verknüpfung der Texte des TLG mit weiteren Volltextdatenbanken für Quellen (PDL) oder für Forschungsliteratur (JSTOR) ermöglicht vernetztes digitales Arbeiten mit griechischen Textquellen für die Alte Geschichte.
Die Library of Latin Texts Complete Plus umfasst die beiden zuvor separaten Datenbanken Library of Latin Texts – Series A (LLT-A) und Series B (LLT-B). Inkludiert sind inzwischen mehr als 5.400 Werke von etwa 1.300 Autoren von den Anfängen der lateinischen Literatur im 3. Jh. v. Chr. bis zum 2. Vatikanischen Konzil (1962–1965): römische Klassiker, Kirchenväter, mittelalterliche lateinische Literatur sowie Texte der Reformation und Gegenreformation. Volltextsuche und Textanalyse ermöglichen vielfältige philologische Fragestellungen.
Die Sammlung Tusculum Online basiert auf der traditionsreichen Buchreihe mit inzwischen mehreren Hundert Bänden. Sie umfasst Editionen, Übersetzungen und Kommentare der griechischen und lateinischen Klassiker der Antike, künftig auch spätantiker, christlicher, byzantinischer und neulateinischer Literatur, basierend auf den teilweise vergriffenen Druckausgaben. Im Gegensatz zur Library of Latin Texts Complete Plus ist in der Sammlung Tusculum Online jedoch keine textübergreifende Volltextsuche möglich, sondern nur in den einzelnen Texten.
Ein umfassendes Informationssystem für die interdisziplinären altertumswissenschaftlichen Disziplinen ist das Portal iDAI.objects (Arachne) des Deutschen Archäologischen Instituts (DAI). Es ist eingebettet in eine modulare Forschungsinfrastruktur, die Objekte, Bücher, Bilder, bibliografische Daten und Forschungsdaten sowie Digitalisate nach einem einheitlichen Datenmodell verwaltet. Für geschichtswissenschaftliches Arbeiten, das sich auf eine breite Vielfalt altertumswissenschaftlicher Quellen stützen möchte, bieten sich hier herausragende Voraussetzungen.
Monumentale Editionen des quellenverliebten 19. Jahrhunderts zur Patrologie- und Mittelalterforschung sind die Patrologia Graeca (PG), die Patrologia Latina (PL) sowie die im folgenden Abschnitt zum Mittelalter besprochenen Monumenta Germaniae Historica (MGH). Die PG basiert auf der Patrologia Graeco-Latina, die von Jacques-Paul Migne zwischen 1857 und 1866 in 161 Bänden herausgegeben wurde.[165] Sie enthält zentrale Werke der christlich-griechischen Kirchenliteratur spätantiker und mittelalterlicher Theologie, Philosophie und Geschichte aus der Zeit zwischen 100 n. Chr. und 1478 und ist grundlegend für historische Forschungen zum frühen Christentum. Die Volltexterschließung erfolgt durch ein lateinisches und griechisches Inhaltsverzeichnis, einen Autoren-, Werktitel- und Sachindex.
In Ergänzung zur PG steht die PL, die Edition des lateinischen Schrifttums der Kirche von den Anfängen bis ins Hochmittelalter in insgesamt 221 Bänden, die Jacques-Paul Migne in zwei Reihen zwischen 1844 und 1855 publiziert hat.[166] Auf dieser Ausgabe beruht die Datenbank, die differenzierte Volltextsuchen ermöglicht. Texte der PL sind auch Bestandteil der Library of Latin Texts.[167]
Zu den zentralen Quellen für die Mediävistik gehören handschriftliche Urkunden, historiographische oder literarische Texte, Inschriften sowie kulturelle Artefakte. Da diese in Archiven, Bibliotheken oder Museen aufbewahrt werden, ist die Kenntnis institutioneller Infrastrukturen hilfreich. Ihre Sammlungen sind häufig Grundlage von Digitalisierungsprojekten und (Volltext-) Datenbanken, die digital vernetztes Arbeiten mit Methoden und Tools der Digital Humanities ermöglichen.
Einen hervorragenden Einstieg in die Überlieferung urkundlicher Quellen bietet Monasterium (MOM), das virtuelle Urkundenarchiv Europas. Es präsentiert etwa 500.000 digitalisierte Dokumente aus mehr als 60 europäischen Archiven – beispielsweise Bilder, Regesten, ältere gedruckte sowie neue Editionen. Eine Volltextsuche innerhalb der Metadaten, aber auch in transkribierten Urkunden, ist möglich.
Die seit dem 19. Jahrhundert entstandenen Handschriftenkataloge einzelner Bibliotheken sind unverzichtbare Instrumente der Text- und Überlieferungsgeschichte. Seit Beginn der Digitalisierung wurden Handschriftenkataloge und Handschriftenoriginale schrittweise digitalisiert und sind Grundlagen von Volltextdatenbanken.
Einen Überblick über das Handschriftenerbe im deutschsprachigen Raum bietet die Recherche in digitalen Handschriftenbibliotheken Deutschlands, Österreichs und der Schweiz. In Deutschland ist das Handschriftenportal (HSP) zentrale Informationsinfrastruktur für europäische Buchhandschriften in deutschen Sammlungen. Recherchierbar sind neben den bibliothekarischen Metadaten der Originale die wissenschaftlichen Beschreibungen der maßgeblichen Handschriftenkataloge. Zugleich ist das HSP zentrales Portal der Handschriftendigitalisate, die sich in den digitalen Bibliotheken der jeweiligen besitzenden Einrichtungen befinden. Durch Technologien wie IIIF erfüllt das HSP internationale Standards der wissenschaftlichen Arbeit mit Digitalisaten. Die dynamische Entwicklung automatischer Volltexterkennung mit HTR lässt Volltextsuchen innerhalb des Handschriftenerbes im HSP vorstellbar werden.
Für die Erforschung der Handschriftenüberlieferung in Österreich koordiniert das Institut für Mittelalterforschung der Österreichischen Akademie der Wissenschaften den Aufbau des Portals manuscripta.at – mittelalterliche Handschriften in Österreich. Sein Ziel, verstreute, schwer zugängliche Daten zu österreichischen Handschriften als Verweise, Links, Images oder Volltexte gebündelt zu präsentieren, macht manuscripta.at dem deutschen Handschriftenportal vergleichbar.
Das schweizerische Pendant e-codices – virtuelle Handschriftenbibliothek der Schweiz erschließt die mittelalterlichen und neuzeitlichen Handschriften aus öffentlichen, kirchlichen und privaten Sammlungen der Schweiz. Als Nationalbibliografie und Bestandsverzeichnis zugleich bietet e-codices den Zugriff auf wissenschaftliche Beschreibungen und digitale Reproduktionen der Handschriften. Es besteht die Möglichkeit, kollaborativ Annotationen oder bibliografische Angaben den einzelnen Handschriften hinzuzufügen.
Neben e-codices weist e-manuscripta.ch digitalisierte handschriftliche Quellen aus Schweizer Bibliotheken und Archiven nach: Texthandschriften (Einzel- und Sammelhandschriften), Briefe, Musikalien, Karten und Bilder. Gemeinsame Transkriptionsarbeit durch moderiertes Crowdsourcing ermöglicht schrittweise eine intellektuelle Volltexttransformation des Handschriftenerbes in der Schweiz – Grundsätze des Open Access und einer Citizen Science verbinden sich harmonisch.
Im Unterschied zu den genannten Portalen, die insbesondere das in Gedächtnisinstitutionen der Schweiz aufbewahrte Handschriftenerbe nachweisen, unterstützt Fragmentarium – Laboratory for Medieval Manuscript Fragments die praktische Forschung und Arbeit mit Handschriftenfragmenten, die internationale „digitale Fragmentologie“.
Ergänzend zu den nationalen Handschriftenportalen im deutschsprachigen Raum bietet der Handschriftencensus (HSC) einen Überblick über sämtliche deutschsprachige Handschriften des Mittelalters aus dem Zeitraum 750–1520 in internationalen Sammlungen. Das umfassende Bestandsverzeichnis bietet differenzierte Informationen und Metadaten zu mittelalterlichen Autoren, Werken und ihrer Überlieferung. Zu jedem Textzeugen ist nicht nur die relevante Literatur bibliografisch erfasst, sondern auch das Digitalisat verlinkt.
Für die Geschichte des Mittelalters bieten klassische Printeditionen die Grundlage von Volltextdatenbanken und komfortable Möglichkeiten des Zugriffs auf Quellen. Unentbehrlich sind die Monumenta Germaniae Historica (MGH) als grundlegende Sammlung von Quelleneditionen (Historiographie, Rechtstexte, Urkunden, Briefe, Dichtung) aus dem Zeitraum 500 – 1500, in der seit 1819 in mehr als 300 Bänden etwa 1.300 Texte erschienen sind. Die aktuellen gedruckten Editionen werden mit einer moving wall von drei Jahren digitalisiert und online publiziert. Differenzierte Suchoptionen ermöglichen einen umfassenden Volltextzugriff auf diese wichtigste Editionsreihe von Quellen zur mittelalterlichen Geschichte Deutschlands und Europas.
Ursprünglich als Vorarbeit zu den MGH konzipiert, entstand mit den Regesta Imperii (RI) ein weiteres Monument der Wissenschaftsgeschichte, das seit seiner Begründung 1839 für Historikerinnen und Historiker unverzichtbar ist. Chronologisch geordnet werden sämtliche urkundlichen und historiographischen Quellen der römisch-deutschen Herrscher von den Karolingern bis zu Maximilian I. (751–1519) sowie der Päpste des frühen und hohen Mittelalters verzeichnet. Bei der Textsorte Regest handelt es sich um keine historisch-kritische Edition, sondern um eine Zusammenfassung des Inhalts der jeweiligen überlieferten Quelle. Sämtliche gedruckten Regestenbände wurden digitalisiert und ihre Inhalte zusätzlich in die Regestendatenbank übernommen. Diese bietet differenzierte Rechercheoptionen in den Volltexten und Vernetzungen beispielsweise mit der Regesta Imperii-Literaturdatenbank (RI-OPAC) als zentraler Bibliografie für die mediävistische Forschung. Sofern eine in den RI erfasste Urkunde innerhalb der MGH ediert wurde, findet sich eine entsprechende Verlinkung.
Eine weitere Verknüpfung der RI besteht mit dem Lichtbildarchiv älterer Originalurkunden Marburg (LBA), das seit 1928 die original überlieferten Urkunden des römisch-deutschen Reiches aus der Zeit vor 1250 sammelt und diese digitalisiert in einer Datenbank zugänglich macht. Die differenzierte Recherchemaske erlaubt beispielsweise die Suche nach Ausstellern, Empfängern, Mitsieglern, Datierungen oder den gegenwärtigen Aufbewahrungsorten von Urkunden. Sind diese innerhalb der RI ediert, gelangt man direkt in die Regesten und kann die Digitalisate unmittelbar vergleichen.
Neben Urkunden sind weitere Textquellen für die Geschichte des Mittelalters relevant. Das Repertorium Geschichtsquellen des deutschen Mittelalters ist ein bibliografisches und quellenkundliches Verzeichnis erzählender Geschichtsquellen wie Chroniken, Annalen oder Briefen aus der Zeit Karls des Großen bis zu Maximilian I. (ca. 750 – 1500). Es ist hervorgegangen aus dem traditionsreichen Repertorium Fontium Historiae Medii Aevi[180]. Neben der Beschreibung des Inhaltes der verzeichneten Quellen finden sich Nachweise der handschriftlichen Überlieferung, der relevanten Editionen, der Übersetzungen und Forschungsbeiträge.
Nicht unerwähnt bleiben soll schließlich eine für die Erforschung des Mittelalters wichtige Volltextdatenbank für epigraphische Zeugnisse, die Deutschen Inschriften Online (DIO). Auf Grundlage der gedruckten Edition Die deutschen Inschriften des Mittelalters und der Frühen Neuzeit[182] hat sie das Ziel, sämtliche lateinischen und deutschen Inschriften bis zum Jahr 1650 aus Deutschland, Österreich und Südtirol zu sammeln und zu edieren. Aufgenommen werden sowohl erhaltene Originalinschriften als auch kopial überlieferte Dokumente. Die Datenbank geht weit über die Digitalisierung der gedruckten Edition hinaus, indem sie weiteres Material integriert und differenzierte Recherchen sowohl in den Einzelbänden, als auch im Gesamtbestand und innerhalb der transkribierten Inschriften ermöglicht.
Bevor sich die Frühe Neuzeit als eigenständige Epoche innerhalb der Geschichtswissenschaft fest etabliert hat, war sie bereits prominenter Gegenstand bibliothekarischer Forschung und bibliografischer Dokumentation.
Insbesondere das als Zeitalter der Inkunabeln, der Wiegendrucke, bezeichnete erste halbe Jahrhundert des Buchdrucks zwischen 1450 und 1500 beschäftigte bereits in der Frühen Neuzeit Bibliothekare und Bibliophile. Im 19. Jahrhundert formierte sich auf Grundlage erster Inkunabelverzeichnisse die Inkunabelkunde als bibliothekswissenschaftliche Disziplin. Diese Verzeichnisse wurden immer vollständiger und immer weiter verbessert, so dass sie inzwischen – wie auch die Handschriftenkataloge – als (Volltext-)Datenbanken mit anderen Forschungsressourcen vernetzt werden können.
Der auf älteren Katalogen[183] aufbauende, an der Königlichen Bibliothek zu Berlin vor dem Ersten Weltkrieg begonnene und heute von der Staatsbibliothek zu Berlin – Preußischer Kulturbesitz fortgeführte Gesamtkatalog der Wiegendrucke (GW) verzeichnet alphabetisch sämtliche Drucke des 15. Jahrhunderts.[185] Da er bis heute nur zu Teilen vollendet ist, wird er parallel als Datenbank aufgebaut, um sämtliche in den gedruckten Bänden sowie im Manuskript nachgewiesenen Inkunabelausgaben in unterschiedlicher Erschließungstiefe zu verzeichnen. Über unterschiedliche Suchmasken und Register lassen sich differenziert Druckernamen, Druckorte, Autoren, Werke oder die GW-Nummern recherchieren.
Wie der deutsche GW verfolgt der von der British Library seit 1980 herausgegebene Incunabula Short Title Catalogue – the international database of 15th-century European printing (ISTC) das Ziel, einen Überblick über die weltweit erhaltenen Inkunabeln zu bieten.[187] Dieser internationale Kurztitelkatalog umfasst als Meta-Katalog die Kerndaten aus nationalen Inkunabelkatalogen mit dem Schwerpunkt auf Europa und Nordamerika. Mit 30.518 Ausgaben (Stand 2016) bietet der ISTC eine hervorragende Abdeckung. Verknüpfungen gibt es mit dem GW und mit vorhandenen Digitalisaten weltweit.
Für Forschungen zur konkreten Materialität von Inkunabeln sind zwei Datenbanken relevant, die mit GW, ISTC und weiteren Inkunabelverzeichnissen verknüpft sind: Material Evidence in Incunabula (MEI) und der von Paul Needham erstellte Index Possessorum Incunabulorum (IPI). In MEI werden sämtliche bekannten materialspezifischen Besonderheiten wie Buchschmuck, Einband, Stempel, Annotationen, Signaturen und Provenienzen erfasst. IPI basiert auf der Auswertung von etwa 200 publizierten Inkunabelkatalogen sowie Needhams eigenen Forschungen zu den früheren Besitzern von Inkunabeln. Insbesondere die Möglichkeit, nach vielfältigsten Provenienzen (zum Beispiel Personen, Institutionen, Monogramme) zu recherchieren, ist eine hervorragende Ergänzung zur Recherche in MEI.
Die größte Inkunabelsammlung des deutschen Sprach- und Kulturraums mit 20.337 Exemplaren von 9.782 Ausgaben besitzt die Bayerische Staatsbibliothek München. Nachgewiesen wird diese im Inkunabelkatalog BSB-Ink online, der auf der zwischen 1988 und 2021 erschienenen Printausgabe[192] beruht und Teil des Inkunabelkatalogs deutscher Bibliotheken (INKA) ist. Die genauen Exemplarbeschreibungen in INKA bieten ein hervorragendes Werkzeug für die Provenienzforschung und referenzieren die maßgeblichen Verzeichnisse und Bibliografien.
Für die Recherche nach Inkunabeln in deutschen und internationalen Sammlungen bieten die genannten Verzeichnisse, auf die vielfach auch der Volltextzugriff möglich ist, eine hervorragende Ausgangsbasis. Wie für Handschriften dürfte auch für die digitalisierten Inkunabeln in absehbarer Zeit eine Volltexterkennung möglich sein, so dass künftig nicht nur in den Inkunabelkatalogen mit sämtlichen Metadaten, sondern auch in den Volltexten der Inkunabeln selbst recherchiert werden kann.
Eine Normierung der Drucktypen und des Textlayouts begann erst im 16. Jahrhundert, in dem mediengeschichtlich die Epoche der Alten Drucke ihren Anfang nahm. Aus der Katalogisierung der deutschen und auf deutschem Territorium erschienenen Drucke des 16., 17. und 18. Jahrhunderts entwickelte sich die retrospektive Nationalbibliografie, die im Rahmen der Arbeitsgemeinschaft Sammlung Deutscher Drucke (AG SDD) zur Verteilten deutschen Nationalbibliothek wurde (vgl. Kap. 1.2). Im Unterschied zu dem zunächst als Druckausgabe erschienenen, erst später in eine Datenbank überführten VD16 wurden VD17 und VD18 von Beginn an als Datenbanken konzipiert. Da zeitgleich um die Jahrtausendwende mit den Digitalisierungszentren in München und Göttingen die Digitalisierung des schriftlichen Kulturerbes begann, konnten mit der autoptischen Katalogisierung der Texte zunächst ausgewählte Schlüsselseiten, später die Werke vollständig digitalisiert werden. Auf Grundlage der retrospektiven deutschen Nationalbibliografie für das 16.–18. Jahrhundert begann die virtuelle digitale deutsche Nationalbibliothek Gestalt anzunehmen. Ihre Volltexttransformation durch Einsatz von OCR-Technologien wird in Zukunft eine Volltextsuche über das gesamte schriftliche Kulturerbe der Frühen Neuzeit ermöglichen.
Da sich die VDs auf die deutschsprachigen oder auf deutschem Territorium gedruckten Werke konzentrieren, ist für die Recherche historischer Drucke auch anderer Sprachen und Herkunft ein weiteres Portal relevant. Das Zentrale Verzeichnis Digitalisierter Drucke (zvdd) ist das Nachweisportal für die in Deutschland erstellten Digitalisate von Druckwerken vom 15. Jahrhundert bis heute – insofern sind auch das 19. und 20. Jahrhundert inkludiert, auch wenn für diesen Bereich angesichts der großen Menge der Drucke sowie ihrer Katalogsituation Vollständigkeit nur schwer zu erzielen ist (vgl. Kap. 1.2). Über eine einheitliche Recherchemaske lässt sich nach Titeln, Autoren, Druckern, Druckorten oder Erscheinungszeiträumen suchen.
Für den deutschsprachigen Raum ist ferner e-rara als Plattform für digitalisierte Drucke aus Schweizer Bibliotheken zu nennen. Nachgewiesen werden Bücher, Karten und illustrierte Materialien von den Anfängen des Buchdrucks bis ins 20. Jahrhundert.
Auch die englische Buchproduktion der Frühen Neuzeit ist in unterschiedlichen Volltextdatenbanken inzwischen ausgezeichnet dokumentiert. Early English Books Online (EEBO) umfasst Bücher aus der Zeit vom Beginn der englischen Buchproduktion bis zu Shakespeare und ist vergleichbar mit VD16 und VD17. Sämtliche Werke sind im Volltext durchsuchbar und können heruntergeladen oder ausgedruckt werden.
Die frühneuzeitliche englische Textproduktion des 18. Jahrhunderts wird außerdem durch die Eighteenth Century Collections Online (ECCO) repräsentiert.[201] Enthalten sind zwischen 1701 und 1800 vorwiegend in England erschienene Bücher, Pamphlete, Essays und Einblattdrucke sämtlicher Fachgebiete. Insbesondere für vergleichende Forschungen zwischen dem deutschen und englischen Kulturraum, beispielsweise zu Fragen der Verbreitung von Autoren, Texten und damit Wissen in der Frühen Neuzeit, bieten EEBO und ECCO einen reichen Schatz an Quellen, dessen systematische Erforschung durch die Verbindung von close reading und distant reading und den Einsatz der Möglichkeiten der Digital Humanities erst am Anfang steht.
Zentrale Gegenstände der Frühneuzeitforschung betreffen die religiösen und sozialen Diskurse im Spannungsfeld von Reformation, Gegenreformation und Dreißigjährigem Krieg. Für den Protestantismus bietet die Digital Library of Classic Protestant Texts (DLCP) Volltexte von etwa 1.500 Werken von mehr als 325 protestantischen Autoren des 16. und 17. Jahrhunderts wie Martin Luther, Johannes Calvin oder Ulrich Zwingli. Neben theologischen Schriften beinhaltet DLCP auch Beichtschriften, Bibelkommentare, Streitschriften, Katechismen und liturgischen Schriften.
Das Pendant für den Katholizismus ist die Digital Library of the Catholic Reformation (DLCR) mit etwa 2.000 Texten katholischer Autoren desselben Zeitraumes. Theologische Schriften sind genauso inkludiert wie Papsturkunden, Synodalbeschlüsse, Katechismen, Beichthandbücher, Bibelkommentare, religiöse Dramen, liturgische Schriften, Inquisitionshandbücher oder Andachtsbücher. In beiden Fällen handelt es sich um kombinierte Volltext- und Faksimiledatenbanken, deren Suchmasken differenzierte Recherchen innerhalb der Volltexte ermöglichen.
In der Frühen Neuzeit gewannen nach der Entdeckung des amerikanischen Kontinents die USA eine immer wichtigere Bedeutung innerhalb der transatlantischen Geschichte. Eine ausgezeichnete Quellengrundlage bietet die Volltextdatenbank Early American Imprints 1639–1819. Innerhalb der Series I: Evans, 1639–1800 (EAI I), die auf der Bibliografie von Charles Evans[206] beruht, finden sich mehr als 36.000 digitale Ausgaben der zwischen 1639 und 1800 in Nordamerika publizierten Bücher.[207] Die Series II: Shaw-Shoemaker, 1801–1819 (EAI II), basierend auf der Bibliografie von Ralph R. Shaw und Richard H. Shoemaker[209], schließt daran an und umfasst 37.000 digitalisierte Werke, die zwischen 1801 und 1819 in Nordamerika erschienen sind.
Wie diese Beispiele zeigen, ist die Epoche der Frühen Neuzeit ein „goldenes Zeitalter für die Retrodigitalisierung“[210]: Die durch Gutenberg eingeläutete Medienrevolution steigerte die Produktion von Schriftlichkeit in zuvor nicht gekanntem Umfang. Insofern bietet sich der Frühneuzeitforschung ein im Vergleich zu vorausgehenden Epochen außerordentlich vielfältiges Portfolio an schriftlichen Quellen. Der in der Regel gute konservatorische Zustand der Bücher dieser Jahrhunderte durch die Verwendung von Hadernpapier sowie die längst erloschenen Urheberrechte geben den Gedächtnisinstitutionen große Freiheiten in ihrer Digitalisierungsentscheidung. Die Volltextdatenbanken, in die die digitalisierten Sammlungen aufgenommen werden, werden zum wichtigsten Instrument frühneuzeitlicher Quellenkunde.
Angesichts der seit dem 19. Jahrhundert weiter expandierenden Schriftlichkeit durch technologische Innovationen der Buchherstellung, neue Textsorten und neue soziale Gruppen von Leserinnen und Lesern stehen der Erforschung der jüngsten Epochen der Geschichte immer neue und immer mehr Quellen zur Verfügung. Begünstigend wirkt, dass OCR-Erkennung moderner Typographien weniger aufwändig ist als im Falle von Inkunabeln, frühen Drucken oder handschriftlichen Dokumenten älterer Epochen.
Ein ähnliches Konzept wie ECCO für englische Quellen des 18. Jahrhunderts verfolgt für das 19. Jahrhundert die Volltextdatenbank Nineteenth Century Collections Online (NCCO). Im Unterschied zu ECCO umfasst sie jedoch ausgewählte internationale Sammlungen aus den Bereichen Geschichte, Politik, Literatur und darstellende Kunst. Im Einzelnen: Asia and the West: Diplomacy and Cultural Exchange, British Politics and Society, British Theatre, Music and the Arts: High and Popular Culture, Europe and Africa: Commerce, Christianity, Civilization, and Conquest, European Literature, 1790–1840: The Corvey Collection[212], Photography: The World Through the Lens und Science, Technology and Medicine, 1780–1925. Die Quellen sind in ihren Metadaten sowie im Volltext differenziert durchsuchbar, ermöglichen einen Download und die Weiterbearbeitung.
Eine wichtige Quellengattung für das 19. und 20. Jahrhundert (und partiell auch für die Frühe Neuzeit), die digitalisiert und in Volltextdatenbanken zur Verfügung steht, sind Zeitungen, für die hier nur einige herausragende Beispiele genannt werden. Eine umfassende Übersicht dazu gibt der Clio-Guide Zeitungen. Grundsätzlich ist zu beachten, dass historische Zeitungen aus der Zeit vor 1945 in der Regel ohne urheberrechtliche Schranken digitalisiert und im Open Access zugänglich gemacht werden können, während für Zeitungen aus der zweiten Hälfte des 20. Jahrhunderts Urheberrechte bestehen. Daher hängt die Nutzungsmöglichkeit von Lizenzen ab – sei es durch die lokale Bibliothek, durch den FID oder als Nationallizenz. Einen jeweils aktuellen Überblick bieten DBIS sowie die jeweiligen Lizenzinformationen der zuständigen FIDs.[214]
Eine breite Titelvielfalt seit dem 16. Jahrhundert bietet der digitale Zeitungs- und Zeitschriftenlesesaal der Österreichischen Nationalbibliothek mit ANNO – Austrian Newspapers Online. Das Portal digiPress präsentiert den historischen Zeitungsbestand der Bayerischen Staatsbibliothek vom 17. Jahrhundert bis ins frühe 20. Jahrhundert mit regionalem Schwerpunkt in Süddeutschland. Der Zugriff auf die Quellen ist über die Titelliste, den Kalender sowie die Volltextsuche möglich. ZEFYS - Zeitungsinformationssystem der Staatsbibliothek zu Berlin besitzt einen regionalen Schwerpunkt im Norden und Nordosten des deutschen Sprachraumes: Die Amtspresse Preußens beispielsweise umfasst zentrale preußische Tageszeitungen der Zeit zwischen 1856 und 1944, das DDR-Presseportal die politisch maßgeblichen Zeitungen der Deutschen Demokratischen Republik der Jahre zwischen 1945 und 1994. Im Hinblick auf eine regionale Abdeckung Deutschlands ist schließlich das Zeitungsportal Nordrhein-Westfalen, zeit.punktNRW, zu nennen, das regionale Zeitungen aus den Bibliotheken und Archiven des Landes mit Volltextsuche digital bereitstellt.
Der Nachweis der Digitalisierungsprojekte zu historischen Zeitungen in Deutschland erfolgt künftig durch das Deutsche Zeitungsportal als Teil der Deutschen Digitalen Bibliothek (DDB).[220] Es wird von mehreren großen Bibliotheken getragen und bietet historische Zeitungen des 17. bis 20 Jahrhunderts mit der Möglichkeit einer Volltextsuche an.
Für Großbritannien sind zwei Volltextdatenbanken für Zeitungen exemplarisch zu nennen: 19th Century British Library Newspapers mit mehr als 160 lokalen und regionalen Zeitungen aus dem Bestand der British Library aus der Zeit von 1732–1950 sowie die Burney collection mit insgesamt 1.270 englischen Zeitungen und Flugschriften des 17. und 18. Jahrhunderts aus der Sammlung des Charles Burney (1757–1817). Mit enthalten sind Parlamentsveröffentlichungen, tagesaktuelle Nachrichten aus London, dem Britischen Empire, den Nachbarländern und deren Königshäusern oder Regierungen.
Für Frankreich steht beispielsweise die einflussreiche Tageszeitung Le Monde als Volltextdatenbank für die Jahre 1944–2000 als FID-Lizenz zur Verfügung.
Vor dem Hintergrund dieser ausgewählten Volltextdatenbanken für Zeitungen einzelner Länder Europas entsteht mit Europeana Newspapers ein gemeinsames Angebot, in dem europäische Zeitungen als historische Quellen künftig vergleichend erforscht werden können.
Erweitert man den Blick von Europa auf die Vereinigten Staaten von Amerika, so stehen auch hier zahlreiche Volltextdatenbanken für Zeitungen zur Verfügung. America‘s Historical Newspapers ist eine umfassende Volltextdatenbank für digitalisierte Zeitungen der USA aus der Zeit zwischen 1690 und 1922. Sie beinhaltet neben überregional bedeutenden Titeln auch Zeitungen aus 50 Bundesstaaten sowie interessante deutsch-amerikanische Periodika. Die Volltextsuche ermöglicht die Analyse politischer und gesellschaftlicher Diskurse auf dem nordamerikanischen Kontinent in einer diachronen Perspektive.
Die großen US-amerikanischen Tageszeitungen, New York Times für die Jahre 1851–2020 und Washington Post für die Jahre 1877–2007 stehen als FID-Lizenzen zur Verfügung. Die Volltextsuche ermöglicht die Recherche innerhalb der einzeln indexierten Artikel, Kommentare, Rezensionen, Fotos, Karikaturen, Werbeanzeigen, Leserbriefe und Familienanzeigen.
Auch das Regierungshandeln des US-Kongresses ist in digitalisierten Quellen ausgezeichnet dokumentiert. Die Volltextdatenbank U.S. Congressional Serial Set 1817–1980/1994 enthält etwa 350.000 Publikationen aus Gremien und Arbeitsgruppen des US-Kongresses sowie von Regierungsbehörden. Teil der Datenbank sind die American State Papers 1789–1838, die Dokumente aus der Periode der ersten 14 US-Kongresse vor 1817 beinhalten. Die Datenbank bietet eine Fülle an Materialien zu allen Bereichen der Geschichte, Politik, Wirtschaft und Kultur der Vereinigten Staaten, aber vielfach auch darüber hinaus, sofern die Beziehungen zu anderen Ländern betroffen sind.
Trotz vielfältiger Schwierigkeiten und Restriktionen bei der Erschließung und Digitalisierung der in osteuropäischen Bibliotheken und Archiven aufbewahrten Quellen existieren inzwischen Volltextdatenbanken zur Geschichte Osteuropas. Integrum World Wide ist die umfangreichste Volltextdatenbank Russlands und der GUS mit etwa 360 Millionen Quellendokumenten aus den Bereichen Politik, Kultur, Wirtschaft und Gesellschaft. Enthalten sind beispielsweise Texte aus der russischen und englischen Presse (regionale und überregionale Periodika, Monitor-Dienste von Fernsehen und Radio, Presseagenturen), Statistiken (Goskomstat), Gesetzestexte, Regierungsveröffentlichungen, Patentschriften (Rospatent), bibliografische Datenbanken der Russischen Akademie der Wissenschaften (INION) oder Internetquellen.
Eine besondere Art Volltextdatenbank stellt das vom Deutschen Historischen Museum (DHM) und Haus der Geschichte (HdG) betriebene Lebendige Museum online (LeMO) dar: Hier werden (Volltext-) Datenbanken musealer Objekte mit Texten, Karten, Statistiken, Bildern sowie Film- und Tondokumenten in einem attraktiven Portal präsentiert.
Das Georg-Eckert-Institut – Leibniz-Institut für Bildungsmedien (GEI), das auch für seine Forschungsaktivitäten im Bereich Volltexterkennnung bekannt ist, bietet in seiner Volltextdatenbank GEI-Digital – Die digitale Schulbuchbibliothek eine Volltextdatenbank für digitalisierte historische Schulbücher, die als Quellen für bildungswissenschaftliche Fragen dienen können.
Welche konkreten Nutzungsszenarien bieten historische Volltext-datenbanken für Historikerinnen und Historiker? Statt zeitinten-siver Bibliotheks- und Archivreisen zu den Originalquellen, statt aufwändiger Suche nach relevanten Textstellen in Quelleneditionen oder Forschungsliteratur ermöglichen Volltextdatenbanken eine zielgenaue Identifizierung relevanter Quellen und Forschungsliteratur sowie den unmittelbaren Zugriff hierauf. Auf Grundlage digitaler Bibliotheken und vernetzter Volltextdatenbanken lassen sich quantitative Analysen historischer Kulturen und Gesellschaften in einem zuvor unbekannten Umfang vornehmen. Beispielsweise ist denkbar, durch automatische Analyse großer Textcorpora von Primärquellen größerer Zeiträume Thesauri historischer Begriffe zu generieren und ihre Semantik differenzierter und umfassender zu analysieren, als es beispielsweise in den Geschichtlichen Grundbegriffen in vordigitaler Zeit möglich war.[234] Künftig wird nicht nur das schriftliche Kulturerbe in einem System vernetzter historischer Volltextdatenbanken zur Verfügung stehen. Es wird möglich sein, Forschungsfragen in einer Qualität und Quantität zu bearbeiten, die in analoger Zeit kaum in einer einzigen Forschergeneration hätten bearbeitet werden können.
Die digitale Transformation verwandelt die traditionelle „Bibliothek der Bücher“ in eine „Bibliothek der Texte“[235], die als Volltexte beliebig kontextualisiert werden können. Text, Mensch und Welt verschmelzen in einem prinzipiell grenzenlosen Hypertext. Texte benötigen keine Bücher mehr – sie haben sich von Büchern und Bibliotheken emanzipiert.[236]
Der Bibliothekskatalog der Zukunft wird nicht mehr nur bibliografische Metadaten von Forschungsliteratur und Standorte gedruckter Bücher nachweisen, sondern als Suchmaschine eine kombinierte Recherche in Metadaten und Volltexten im Textraum sämtlicher digital(isiert)en Bücher und Forschungsressourcen der jeweiligen Bibliothek ermöglichen und den direkten Zugriff auf die Quellen und Volltexte bieten. Doch nicht genug: Lokale Texträume verschmelzen mit globalen Textwelten, in denen geschichtswissenschaftliche Quellen und Forschungsliteratur eine disziplinäre Textsphäre bilden, die verwoben ist mit Textsphären anderer Disziplinen: Interdisziplinäre Volltextrecherchen im universellen Text- und Datenraum global vernetzter digitaler Bibliotheken werden möglich. Bibliotheken haben aber auch in Zukunft die Aufgabe, Bücher, Texte, Informationen, Daten und Wissen für den lesenden Menschen zu strukturieren.
Die digitale Transformation verwandelt die traditionelle „Bibliothek der Bücher“ aber nicht allein in eine „Bibliothek der Texte“, sondern zugleich in eine „Bibliothek der Informationen“ und in eine „Bibliothek der Daten“. Nachdem angesichts der wachsenden Bedeutung von Forschungsdaten innerhalb digital arbeitender Wissenschaften der Rat für Informationsinfrastrukturen (RfII) die Gründung der Nationalen Forschungsdateninfrastruktur (NFDI) angestoßen hat, befinden sich mehrere geisteswissenschaftliche Konsortien im Aufbau.[239] Vertreten durch den Verband der Historiker und Historikerinnen Deutschlands (VHD) sind die Geschichtswissenschaften Teil des NFDI4Memory-Konsortiums, das Forschungseinrichtungen, Gedächtnisinstitutionen und Informationsinfrastrukturen aus den historisch arbeitenden Geisteswissenschaften vereint.[241]
Historische Forschungsdaten („historical research data“) werden sehr breit verstanden: „Under the broad label of ‚data‘ one finds texts (handwritten or printed), images, objects, statistical databases, maps, and films, among others, each with their own specificities and challenges. Different types of data and different research methods require modular and flexible solutions that currently only exist in limited contexts.“[242] Kernziele von NFDI4Memory sind: „Linking Research, Memory Institutions and Infrastructures“, „Integrating Historical Source Criticism into Data Services“, „Network of Historically Oriented Research Communities“, „Knowledge Order for the Digital Future of the Past“, „Advancing the Analog / Digital Interface of Historical Source Material and Data“, „Generating Standards for Historical Research Data and Sustainability“, „Education and Citizen Participation“.[243] Ein zentrales Anliegen von NFDI4Memory ist es, die spezifische Tradition der Quellenkritik für das digitale Zeitalter im Sinne einer digitalen Quellenkritik weiterzuentwickeln. Auf diese Weise können aus geschichtswissenschaftlicher Perspektive im Zeitalter der Digital Humanities die „Bibliothek der Bücher“, die „Bibliothek der Texte“ und die „Bibliothek der Daten“ durchaus zusammengedacht werden.[244]
Neben NFDI4Memory sind für geschichtswissenschaftliches Arbeiten weitere NFDI-Konsortien relevant: Text+ als Konsortium für Sprach- und textbasierte Forschungsdateninfrastruktur, NFDI4Culture als Konsortium für Forschungsdaten zu materiellen und immateriellen Kulturgütern und NFDI4Objects – Forschungsdateninfrastruktur für die materiellen Hinterlassenschaften der Menschheitsgeschichte. Vergleichbar mit den früheren SSGs oder FIDs der Bibliotheken entstehen innerhalb der NFDI Informationsinfrastrukturen für Forschungsdaten, bei denen nicht nur Bibliotheken, sondern zahlreiche weitere Partner eng zusammenwirken.
Volltextdatenbanken zählen zu den wichtigsten Instrumenten historischen Arbeitens, sei es für Quellen, Quelleneditionen oder Forschungsliteratur. Die technisch realisierte Volltexterkennung wird zum „Qualitätskriterium von digitalen Sammlungen“[248]. Da geschichtswissenschaftliches Arbeiten in der Regel mit einer Recherche nach Fachliteratur zu einem Thema in einer bibliografischen Datenbank beginnt, bieten historische Volltextdatenbanken die komfortable Möglichkeit, aus dieser Recherche heraus über Linkresolver direkt zum Volltext innerhalb einer Volltextdatenbank zu gelangen. Immer häufiger entwickeln sich bibliografische Datenbanken auch selbst zu Volltextdatenbanken, so dass die bibliografische Recherche unmittelbar zum Volltext der Forschungsliteratur führt. Geschichtswissenschaftliches Arbeiten bedeutet aber auch die intensive Arbeit mit Quellen. Wie Forschungsliteratur werden diese ebenfalls nicht nur als digitale Faksimiles reproduziert, sondern durch Anwendung der HTR/OCR-Technologien in Volltextdatenbanken aufbereitet.
Das Ziel, das gesamte handschriftliche und gedruckte Kulturerbe aus Antike, Mittelalter und Neuzeit digital zu faksimilieren und im Volltext zu erkennen, liegt für den deutschen Sprachraum inzwischen in greifbarer Nähe. Die für die Geschichtswissenschaft zentralen Schriftquellen werden sich künftig als fortlaufender und vernetzter Text vor den Augen der Lesenden entfalten. Es wird möglich sein, nicht nur innerhalb der Kontinente digital verfügbarer Forschungsliteratur und Forschungsdaten, sondern zugleich innerhalb des digitalisierten schriftlichen Kulturerbes zu „googeln“.
In beiden Fällen – Volltextdatenbanken für Forschungsliteratur und Volltextdatenbanken für Quellen – ermöglicht eine Volltextsuche die Formulierung von Fragen und die Gewinnung von Erkenntnissen, für die eine automatisierte Analyse großer Textmengen durch corpusbasierte Forschungsfragen grundlegende Voraussetzung ist. Volltextdatenbanken sind somit weit mehr als nur eine neue Form der Publikation und Archivierung zuvor gedruckten oder genuin digital repräsentierten Wissens, indem sie differenzierte Instrumente der Erschließung und Analyse von Texten bereitstellen und neue Fragestellungen und Antworten ermöglichen. Auch in den nächsten Jahren ist mit einer kontinuierlichen Zunahme von Volltextdatenbanken zu rechnen, da nicht nur immer größere Textmengen erstmals digitalisiert sind, sondern auch viele der bisher lediglich in Image-Digitalisaten vorliegenden Sammlungen mit automatischen Texterkennungsverfahren aufbereitet werden.
Vor dem Hintergrund der skizzierten Entstehung und Charakterisierung historischer Volltextdatenbanken lassen sich bereits jetzt Szenarien der Zukunft erkennen, in denen historische Volltextdatenbanken ihre Potenziale vollends entfalten können. Insbesondere ist zu erwarten, dass die beiden Säulen geschichtswissenschaftlichen Arbeitens mit Texten – das Studium der Quellen und der Forschungsliteratur – durch immer umfassendere Volltextdatenbanken ganz neue Qualitäten ermöglichen. Zugleich werden diese Textwelten immer differenzierter miteinander verwoben – Quellen mit Quellen, Quellen mit Forschungsliteratur und Forschungsliteratur mit Forschungsliteratur. In Bezug auf den Umgang mit historischen Quellen tritt neben die Kompetenzen in traditionellen historischen Grundwissenschaften wie Paläographie oder Kodikologie die digitale Quellenkritik. Insbesondere für Forschungsprojekte im Kontext historischer Volltextdatenbanken spielen die Fächer Informatik, Informationswissenschaft und Bibliothekswissenschaft eine gleichermaßen zentrale Rolle.
Künftig werden sich nicht nur menschliche Historikerinnen und Historiker in diese Textwelten von Quellen und Forschungsliteratur begeben, um in individueller oder kollaborativer Forschung zu neuen Erkenntnissen zu gelangen. Je mehr Texte digitalisiert, volltexterkannt und prozessierbar für weitere Bearbeitung gemacht werden, je mehr Texte als genuine Open-Access-Publikationen vorliegen, desto größere Potenziale gewinnen nicht nur Algorithmus-basierte Analyseverfahren wie Text Mining, sondern auch KI-Technologien wie Large Language Models (LLMs).[249]
Bereits jetzt ist überdeutlich, dass sich (geschichts-)wissenschaftliches Arbeiten in Zukunft fundamental ändern wird. Historikerinnen und Historiker werden weiterhin forschungsrelevante Fragen auf der Basis intensiver Lektüre von Quellen und Forschungsliteratur bearbeiten. Historische Kompetenz wird zunehmend jedoch auch darin bestehen, KI-basierte oder durch den Einsatz von KI ergänzte Analysen zu prüfen und fachlich zu bewerten. Beschleunigtes distant reading, durch das Quellen und Forschungsliteratur schneller aufgefunden oder analysiert werden können, ermöglicht mehr Zeit für interpretatorische Arbeit im close reading. Geschichtswissenschaftliches Arbeiten basiert künftig nicht nur auf einer fundierten Fachkompetenz, die sich durch Anwendung klassischer hermeneutischer Verfahren auszeichnet, sondern gleichermaßen auf einer fundierten Informations-, Medien-und Datenkompetenz, die einer stetig wachsenden Menge verfügbarer wissenschaftlicher Informationen souverän begegnet, und schließlich auf einer fundierten Datenkompetenz, die mit unterschiedlichsten historischen Daten umzugehen weiß. Hierzu gehören beispielsweise Metadaten von Digitalisaten historischer Quellen oder TEI/XML-Code, mit dem Texte ausgezeichnet werden, um beispielsweise digitale Editionen zu erstellen.
Innerhalb des Prozesses, den die traditionelle, analoge Geschichtswissenschaft über die Digitalisierung hin zur digitalen Transformation durchläuft, nehmen historische Volltextdatenbanken eine Schlüsselrolle ein: An ihnen werden zahlreiche Aspekte dieses Wandels exemplarisch deutlich. Selbstverständlich untersuchen auch heute noch Historikerinnen und Historiker originale historische Quellen. Sofern von diesen analogen Originalquellen jedoch digitale Repräsentationen wie digitale Faksimiles oder Transkriptionen hergestellt werden, ist auch mit diesen im Forschungsprozess umzugehen. Ein weiterer Quellentypus, der für die Zeitgeschichte immer wichtiger wird, sind Quellen, die „digital born“ sind, wie beispielsweise elektronische Akten oder Postings in Sozialen Netzwerken. Da sich digitale Quellen beliebig kopieren lassen, stellt sich nicht nur die Frage nach möglichen Unterscheidungskriterien zwischen Original und Kopie im Digitalen, sondern auch die grundsätzliche Frage nach einer zeitgemäßen Quellenkritik. Eine solche „digitale Quellenkritik“ sollte eingebettet sein in eine „digitale Hermeneutik“, wie sie Andreas Fickers vorschlägt: „Es ist höchste Zeit, die digitale Hermeneutik zu entwickeln und sie zum Standard für die Ausbildung zukünftiger Historiker zu machen […] Die Sprachen des Historikers waren lange Zeit tote Sprachen wie Latein oder Altgriechisch. Der Geschichtswissenschaftler der Zukunft muss neben diesen auch Programmiersprachen verstehen.“[250]
Geschichtswissenschaftliche Informations- und Medienkompetenz, Datenkompetenz sowie digitale Quellenkritik sind künftig die Säulen, auf denen die Grundsätze guter wissenschaftlicher Praxis ruhen – gerade auch im Hinblick auf die Einbindung von Methoden künstlicher Intelligenz. Geschichtswissenschaftliches Arbeiten in der digitalen Welt bietet eine Vielzahl von Perspektiven und Potenzialen, die in Gestalt historischer Volltextdatenbanken in nuce erkennbar sind.
Adams, Thomas R.; Barker, Nicolas, A New Model for the Study of the Book, in: A Potencie of Life. Books in Society. The Clark Lectures 1986–1987, Hrsg. von Nicolas Barker, London 1993, S. 5–43.
Blickle, Peter, Die Revolution von 1525, 4., durchgesehene und bibliografisch erweiterte Auflage, München 2004.
Bösch, Frank; Schlotheuber, Eva, Quellenkritik im digitalen Zeitalter: Die Historischen Grundwissenschaften als zentrale Kompetenz der Geschichtswissenschaft und benachbarter Fächer, in: Historische Grundwissenschaften und die digitale Herausforderung, Hrsg. für H-Soz-Kult von Rüdiger Hohls, Claudia Prinz und Eva Schlotheuber, Historisches Forum 18 (2016), S. 16–20,
https://edoc.hu-berlin.de/handle/18452/19491.
Darnton, Robert, What is the History of Books?, in: Daedalus 111 (1982), S. 65–83.
Darnton, Robert, What is the History of Books?, in: Modern Intellectual History 4 (2007), S. 495–508.
Deck, Klaus-Georg, Digital Humanities – Eine Herausforderung an die Informatik und an die Geisteswissenschaften, in: Wie Digitalität die Geisteswissenschaften verändert: Neue Forschungsgegenstände und Methoden, hrsg. von Martin Huber und Sybille Krämer, 2018 (= Sonderband der Zeitschrift für digitale Geisteswissenschaften, 3),
https://doi.org/10.17175/sb003_002.
Digital Humanities in den Geschichtswissenschaften, hrsg. von Christina Antenhofer, Christoph Kühberger und Arno Strohmeyer, Wien 2024.
Enderle, Wilfried, Frühe Neuzeit, in: Clio Guide – Ein Handbuch zu digitalen Ressourcen für die Geschichtswissenschaften, hrsg. von Silvia Daniel, Wilfried Enderle, Rüdiger Hohls, Thomas Meyer, Jens Prellwitz, Claudia Prinz, Annette Schuhmann, Silke Schwandt, 3. erw. und aktualisierte Aufl., Berlin 2023,
https://doi.org/10.60693/yqjz-7f44.
Eisermann, Falk, The Gutenberg Galaxy’s Dark Matter: Lost Incunabula, and Ways to Retrieve Them, in: Flavia Bruni und Andrew Pettegree (Hrg.), Lost Books. Reconstructing the Print World of Pre-Industrial Europe. Leiden/Boston: Brill 2016, S. 31–54.
Engl, Elisabeth, OCR-D kompakt. Ergebnisse und Stand der Forschung in der Förderinitiative, in: Bibliothek – Forschung und Praxis 44 (2020), 2, S. 218–230,
https://doi.org/10.1515/bfp-2020-0024.
Ernst, Michael, Rechtliche Rahmenbedingungen der Digitalisierung kulturellen Erbes. Legal framework for digitising cultural heritage, in: Bibliotheksdienst 52 (2018) 9, S. 687–697;
http://doi.org/10.1515/bd-2018-0082.
Euler, Ellen, Open Access, Open Data und Open Science als wesentliche Pfeiler einer (nachhaltig) erfolgreichen digitalen Transformation der Kulturerbeeinrichtungen und des Kulturbetriebes, 2018,
https://doi.org/10.11588/artdok.00006135.
Fabian, Bernhard, Buch, Bibliothek und geisteswissenschaftliche Forschung. Zu Problemen der Literaturversorgung und Literaturproduktion in der Bundesrepublik Deutschland, Göttingen 1983.
Gasser, Sonja, Das Digitalisat als Objekt der Begierde. Anforderungen an digitale Sammlungen für Forschung in der Digitalen Kunstgeschichte, in: Objekte im Netz. Wissenschaftliche Sammlungen im digitalen Wandel, Hrsg. von Udo Andraschke, Sarah Wagner, Bielefeld 2020, S. 261–276, https://doi.org/10.1515/9783839455715-009.
Haber, Peter, Digital Past. Geschichtswissenschaft im digitalen Zeitalter, München 2011.
Hertling, Anke; Klaes, Sebastian, Volltexte für die Forschung: OCR partizipativ, iterativ und on Demand, in: O-Bib. Das offene Bibliotheksjournal 9 (2022) 3, S.1–11,
https://doi.org/10.5282/o-bib/5832.
Huff, Dorothee; Stöbener, Kristina, Projekt OCR-BW: Automatische Texterkennung von Handschriften, in: O-Bib. Das Offene Bibliotheksjournal 9 (2022) 4, S. 1–19,
https://doi.org/10.5282/o-bib/5885.
Johrendt, Jochen, Digitalisierung als Chance, in: Historische Grundwissenschaften und die digitale Herausforderung, Hrsg. für H-Soz-Kult von Rüdiger Hohls, Claudia Prinz und Eva Schlotheuber, Historisches Forum 18 (2016), S. 41–42,
https://edoc.hu-berlin.de/handle/18452/19491.
Kann, Bettina, Hintersonnleitner, Michael, Volltextsuche in historischen Texten – Erfahrungen aus den Projekten der Österreichischen Nationalbibliothek, in: Bibliothek – Forschung und Praxis 39 (2015) 1, S. 73–79,
http://doi.org/10.1515/bfp-2015-0004.
Kobel, Esther; Volp, Ulrich, Distant reading – Perspektiven einer digitalen Zeit. Eine Einführung, in: Journal of Ethics in Antiquity and Christianity 4 (2022), S. 5–10.
Lauer, Gerhard, Was ist Buchwissenschaft, wenn sie eine Disziplin ist?, in: Archiv für Geschichte des Buchwesens 77 (2022), S. 173–178.
McLuhan, Marshall, Die Gutenberg-Galaxis. Das Ende des Buchzeitalters, München 1968.
McLuhan, Marshall; Powers, Bruce R., The global village: der Weg der Mediengesellschaft in das 21. Jahrhundert, Paderborn 1995.
Mühlberger, Günter, Digitalisierung historischer Zeitungen aus dem Blickwinkel der automatisierten Text- und Strukturerkennung (OCR), in: Zeitschrift für Bibliothekswesen und Bibliographie 58 (2011), 1, S. 10–18,
http://doi.org/10.3196/186429501158135.
Otlet, Paul, Traité de documentation. Le livre sur le livre. Théorie et pratique, Brüssel 1934.
Rautenberg, Ursula (Hrsg.), Buchwissenschaft in Deutschland. Ein Handbuch, Berlin - Boston 2010.
Rehbein, Malte, Digitalisierung braucht Historiker/innen, die sie beherrschen, nicht beherrscht, in: Historische Grundwissenschaften und die digitale Herausforderung, Hrsg. für H-Soz-Kult von Rüdiger Hohls, Claudia Prinz und Eva Schlotheuber, Historisches Forum 18 (2016), S. 45–52,
https://edoc.hu-berlin.de/handle/18452/19491.
Sahle, Patrick, Digitale Editionsformen: zum Umgang mit der Überlieferung unter den Bedingungen des Medienwandels, 3 Bände, Norderstedt 2013.
Sahle, Patrick, Digitale Edition, in: Jannidis, Fotis; Kohle, Hubertus; Rehbein Malte (Hrsg.): Digital Humanities: Eine Einführung, Stuttgart 2017, S. 234–249.
Schmitz, Wolfgang, Grundriss der Inkunabelkunde. Das gedruckte Buch im Zeitalter des Medienwechsels, Stuttgart 2023.
Stäcker, Thomas, Konversion des kulturellen Erbes für die Forschung: Volltextbeschaffung und -bereitstellung als Aufgabe der Bibliotheken, in: O-Bib 1 (2014), S. 220–237.
http://doi.org/10.5282/o-bib/2014H1S220-237.
Steinhauer, Eric W., Die Bibliothek 2040 – eine Einrichtung der digitalen Transformation mit vielen Büchern?, in: Bibliothek: Forschung und Praxis 47 (2023) 1, S. 29–32, ,
https://doi.org/10.1515/bfp-2023-0014.
Zotter, Hans, Erlebnisräume, gebaut aus Erinnerungen. Die Sondersammlung als Teaching Library, in: Sondersammlungen im 21. Jahrhundert: Organisation, Dienstleistungen, Ressourcen, Hrsg. von Graham Jefcoate, Jürgen Weber, Wiesbaden 2008, S. 136–144.
Dr. Marcus Schröter ist Leiter des Dezernats Historische Sammlungen, Digitalisierung, Bestandserhaltung und Fachreferent für Geschichtswissenschaften und Buchwesen an der Universitätsbibliothek Freiburg im Breisgau. Neben seiner Lehrtätigkeit in Freiburg unterrichtet er an der Bibliotheksakademie Bayern. Seine Arbeitsschwerpunkte sind Buch- und Bibliotheksgeschichte, Editionswissenschaft, Digitalisierung und Digital Humanities sowie Didaktik der Informations- und Medienkompetenz.